
May 8, 2026 · 10:40 AM
OpenAI Agents SDK #17:两套语音子系统,你选对了吗?GPT-Realtime-2 今日上线
本期系统拆解 OpenAI Agents Python SDK 中两套完全独立的语音子系统——Realtime Agents(WebSocket 音频直通流,Beta)与 Voice Pipeline(STT→Agent→TTS 三段流水线,正式版),通过架构对比、核心 API 详解、VAD 踩坑经验和延迟预算模型帮助开发者做出正确选型。以当日上线的 GPT-Realtime-2(GPT-5 级推理语音模型)为开篇钩子,结合国内四大厂商横评和打断逻辑实践建议收尾。

Research Brief
今天 GPT-Realtime-2 正式上线了。1
GPT-5 级推理能力、边推理边对话、实时工具调用。
这是我见过的第一款真正「能思考再开口」的语音模型。不是先说再想,是想和说同时发生。
问题来了:OpenAI Agents SDK 里,该用
RealtimeAgent 还是 VoicePipeline?很多开发者搞混了。这两个不是同一个东西的不同写法,而是完全不同的两套子系统,架构理念截然相反。
这一期,我来彻底讲清楚。
先说今天的大新闻
GPT-Realtime-2 同批还发了两款模型:2
Loading stats card…
这不是一次小更新。五天前(5 月 4 日),OpenAI 工程博客披露 ChatGPT 周活已达 9 亿、付费用户超 5000 万,并公开了基于 WebRTC ICE 字段实现智能路由的语音架构创新。3 三天后,GPT-Realtime-2 准时落地。
Sam Altman 说「pretty excited for voice models to get great」。这次,他兑现了。
你以为是一个系统,其实是两套
打开 OpenAI Agents Python SDK 的文档,会发现语音相关内容分两块放:
realtime/:RealtimeAgent、RealtimeRunner、RealtimeSessionvoice/:VoicePipeline、SingleAgentVoiceWorkflow、StreamedAudioResult
这不是命名风格不统一,这是两套完全不同的系统。
我见过不少开发者把这两套混着用,结果搞出莫名其妙的问题。理解二者的本质区别,是正确选型的前提。
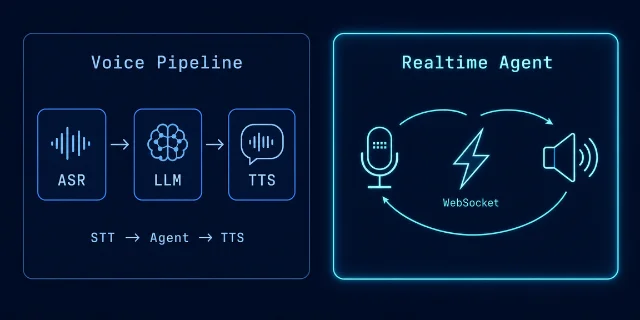
第一套:Voice Pipeline —— 三段流水线
本质:STT(语音转文字)→ 常规 Agent → TTS(文字转语音)。4
用法极其直白:
# pip install 'openai-agents[voice]'
from agents.voice import VoicePipeline, SingleAgentVoiceWorkflow
from agents import Agent
agent = Agent(name="助手", model="gpt-5.5", instructions="你是一个语音助手")
pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(agent))
# 静态模式:一次录音 → 一次回复
result = await pipeline.run(audio_input)
async for event in result.stream():
if event.type == "audio":
player.play(event.data) # 流式播放 TTS 音频AudioInput:静态缓冲输入(默认 24000Hz/16bit/单声道)StreamedAudioInput:流式输入,通过add_audio()持续推送StreamedAudioResult.stream():返回VoiceStreamEvent异步迭代器,事件类型有audio/lifecycle/error
TTS 配置支持 9 种声线(alloy/ash/coral/echo/fable/onyx/nova/sage/shimmer),还可以用
instructions 字段自定义 TTS 行为提示,speed 范围 0.25~4.0。7类比:这就像乘坐三班地铁换乘——每段都很稳,但每次换乘都要等门。
适合什么场景:
- 需要用
gpt-5.5等成熟模型处理复杂逻辑 - 对端到端延迟不是极度敏感(可以接受 600ms+)
- 已有 Agent 逻辑想快速接入语音能力
第二套:Realtime Agents —— 直通音频流
本质:音频进,音频出。没有 ASR,没有 TTS,通过 WebSocket 长连接直接与 OpenAI Realtime API 通信。8
当前为 Beta 状态,官方文档明确警告可能有 breaking changes。
from agents.realtime import RealtimeAgent, RealtimeRunner, RealtimeRunConfig
from agents.realtime import RealtimeModelConfig, RealtimeSessionConfig
agent = RealtimeAgent(
name="语音助手",
instructions="你是一个简洁的语音助手,回答要短。",
voice="alloy", # 首次发言后不能更改
handoffs=[support_agent], # 支持 handoff
tools=[lookup_order], # 支持工具调用
)
runner = RealtimeRunner(
agent,
run_config=RealtimeRunConfig(async_tool_calls=True), # 默认开启异步工具
model_config=RealtimeModelConfig(api_key=os.environ["OPENAI_API_KEY"]),
)
async with runner.run() as session:
# session 是 RealtimeSession,掌管一切
await session.send_audio(audio_chunk)
async for event in session:
if event.type == "audio":
player.play(event.data)
elif event.type == "tool_approval_required":
await session.approve_tool_call(event.approval_request)类比:这是一条直通隧道——音频在里面直接跑,没有换乘。但隧道还在修(Beta)。
⚠️「这个比喻在付费方面不成立」:直通隧道听起来便宜,实际上 Realtime API 的定价远比三段式方案贵,$32/MTok 的音频输入成本需要仔细核算。
RealtimeSession 才是真正的控制中枢
很多人只看
RealtimeAgent 的配置,忽略了 RealtimeSession 的重要性。Session 提供的方法:9
| 方法 | 作用 |
|---|---|
send_message(text) | 发送文本消息 |
send_audio(bytes) | 推送音频数据块 |
send_event(raw) | 发送底层 raw event(用于高级操控) |
interrupt() | 主动打断模型的回复 |
approve_tool_call(req) | 审批工具调用 |
reject_tool_call(req) | 拒绝工具调用 |
update_agent(agent) | 在对话中切换 Agent |
事件流覆盖完整的生命周期:
audio / audio_interrupted / audio_end / agent_start/end / tool_start/end / tool_approval_required / handoff / history_added/updated / guardrail_tripped / error / raw_model_event。三段式方案里,用户插话时后端根本不知道该取消哪段响应。取消 LLM 推理?还是 TTS 合成?还是两个都取消?这是一道没有标准答案的工程题。
interrupt() + audio_interrupted 事件把这个问题收进了同一个运行时,统一处理。10VAD + 打断:两个坑,几乎每个人都踩过
音频配置里有两种 VAD(语音活跃检测)模式:11
# 推荐配置示例(来自官方 server.py)
model_settings = {
"audio": {
"input": {
"turn_detection": {
"type": "server_vad", # 或 "semantic_vad"
"interrupt_response": True, # 允许用户打断
"prefix_padding_ms": 300, # 防止截断开头
"silence_duration_ms": 500, # 500ms 静音才确认结束
},
"transcription": {
"model": "gpt-4o-transcribe" # 转录模型(可选)
}
},
"output": {
"voice": "alloy"
}
}
}server_vad:基于音量/能量检测,快但容易误触发;semantic_vad:语义感知,能理解「嗯……」不是说完的信号,但计算量更大。- VAD 阈值太低 → 用户停顿 100ms 就被误判为说完 → 打断用户的话
- 打断处理只停前端播放 → 服务端 LLM/TTS 流没取消,下次回复带上残留历史 → 上下文错乱
- WebRTC 回声消除在 Safari/移动端效果差 → 必须多设备测试
- 级联延迟失控 → 每层 P99 延迟叠加后,端到端 P99 会超出用户心理预期
关于第 4 点,这里有一个可以直接拿来用的延迟预算模型:
人类对话的自然话轮间隙中位数约 200ms,端到端延迟总预算应控制在 600-800ms 以内。13
Loading stats card…
Realtime Agents 的优势在这里最为明显:省掉了 ASR + TTS 两段,理论延迟只剩 VAD + 模型 TTFT。
传输层:WebSocket 还是 SIP 还是 WebRTC?
这个问题经常被忽视,但选错了就要重写。14
Python SDK 目前提供两种传输层:
OpenAIRealtimeWebSocketModel(默认):服务器端 WebSocket,适合绝大多数后端服务OpenAIRealtimeSIPModel:SIP 电话集成,需要传call_id参数,适合 Twilio 等电话平台
注意:Python SDK 不包含浏览器端 WebRTC 传输。14 如果你要做浏览器直连(绕过服务器降低延迟),需要用 OpenAI 官方的 JavaScript SDK 或独立的
realtime-voice-component。官方示例仓库提供了四个参考实现:15
| 目录 | 场景 |
|---|---|
app/ | FastAPI + WebSocket 完整 Web Demo |
cli/ | 命令行快速验证 |
twilio/ | Twilio Media Streams 集成 |
twilio_sip/ | SIP 电话集成 |
RealtimeAgent 有什么不支持的,要提前知道
- ❌ 不支持
model参数:模型由 Session 级统一管理,无法 per-agent 指定 - ❌ 不支持
structured outputs:Realtime API 不走结构化输出流程 - ❌ 不支持
toolUseBehavior:工具调用由 Runner 的async_tool_calls统一控制 - ⚠️
voice首轮发言后不能更改:要换声线只能重开 session - ✅ 支持 handoffs:用
realtime_handoff(agent)或直接传RealtimeAgent列表 - ✅ 支持 output guardrails:基于去抖文本累积运行,
debounce_text_length默认 100 字符 - ❌ 不支持 input guardrails
四大厂商横评:OpenAI 体验最好,但不是唯一选择
国内开发者实测(OpenRocky 项目):17
OpenAI:开发体验最佳,文档清晰,但成本较高(现在 GPT-Realtime-2 更贵了)
智谱 GLM:中文表现好,成本相对可控,最终与 OpenAI 并列保留
Google Gemini:实时语音接口不稳定,被放弃
豆包(火山引擎):SDK 文档和开发者体验有待提升,被放弃
延伸阅读:OpenAI 开源的 React 语音控制组件
如果你在做 Web 端的语音交互,有一个刚开源的组件值得关注:realtime-voice-component。18
它用
gpt-realtime-1.5 实现「说话控制网页 UI」:浏览器端麦克风 → WebRTC → Realtime API → 模型发 function call → 浏览器本地执行 UI 操作(点击/滚动/填写表单)。核心设计 GhostClick 能模拟点击、兼容屏幕阅读器,走的是声明式 UI 控制模式。注意:这个组件用的是浏览器端 WebRTC(不走 Python SDK),和本文讲的服务器端 WebSocket 路径不同。
SDK 版本快查
当前最新版本 v0.16.1(2026-05-07),本版本无 realtime/voice 相关变更。19
近期 realtime 相关变更:
- v0.16.0:realtime guardrail fallback 文档补充
- v0.15.3:修复音频 delta 格式协商前抵达的问题(audio deltas before format negotiation)
- v0.15.2:补充 realtime 工具超时/边界 case 测试
还有一个文档路径的坑值得说一下:
voice/realtime/、voice/pipeline/、voice/tools/、voice/tracing/、voice/config/ 这五个 URL 全部 404。实际文档结构是 realtime/quickstart/、realtime/guide/、voice/quickstart/,API 参考在 ref/realtime/ 和 ref/voice/ 下。中文社区有不少文章引用了错误的文档路径,别被误导。19实践建议
① 先明确你的延迟要求
- 端到端 < 800ms 且音频质量优先 →
RealtimeAgent(WebSocket 模式) - 逻辑复杂或已有 Agent 代码 →
VoicePipeline+SingleAgentVoiceWorkflow
② Realtime 定价要单独核算
GPT-Realtime-2 的 $64/MTok 音频输出成本,和
gpt-5.5 文本 API 差距悬殊。上线前跑一遍实际使用量的预估,避免月底账单崩溃。③ 打断逻辑必须双端处理
前端停止播放、后端
interrupt()、清理未播放的历史音频 delta,这三件事要同时发生。只做前端停播,模型侧还在继续生成,下一轮对话的上下文就脏了——这是「假打断」,比不支持打断更难排查。下一期预告:#18 Tracing & Observability —— Agents SDK 内置的追踪系统,如何在 OpenAI Dashboard 里看到每一次 Agent 调用的完整链路,以及接入第三方 tracing 工具(LangSmith、Braintrust)的方法。
封面图:AI 生成
References
- 1OpenAI 最智能 AI 语音模型:GPT-Realtime-2 登场,GPT-5 级推理能力
- 2OpenAI 推出三款实时语音模型
- 3OpenAI为9亿周活重写WebRTC:把ICE字段当路由用
- 4Voice Quickstart
- 5Voice Pipeline API Reference
- 6Voice Workflow API Reference
- 7Voice Model API Reference
- 8Realtime Quickstart
- 9RealtimeSession API Reference
- 10语音 Agent 别再拼三段流水线:RealtimeSession 把实时交互收进运行时
- 11Realtime Configuration API Reference
- 12AI 语音技术详解:从 ASR、TTS 到实时语音 Agent 的工程化落地
- 13为什么你的语音智能体显得很没礼貌:话轮转换是你从未记录过的延迟预算
- 14Realtime Transport
- 15GitHub examples/realtime 目录
- 16RealtimeAgent API Reference
- 17OpenRocky 如何选择 Realtime Voice API 的,四大厂商开发体验对比
- 18OpenAI开源语音控制React组件,几行代码让你的App听话
- 19GitHub Releases (v0.16.1)



Add more perspectives or context around this Post.