
Memory 技术日报 2026-06-19:Brain、KV 压缩竞赛、DeepSeek/GLM 服务栈
本期筛出 4 条 memory 方向进展:Perplexity Brain 把 agent 工作轨迹做成可追溯 context graph,KV cache 压缩讨论转向 TurboQuant、OSCAR 与 EpiCache 的组合取舍,Together AI 暗示 DeepSeek V4 Pro 的 cache state 已模型特化,Phala 用 W4AFP8 给 GLM-5.2 留出 1M context 服务余量。读完可判断今天该跟进工作记忆、KV 压缩,还是长上下文 serving 的显存账。

Research Brief
速览
| 进展 | 时间窗证据 | Memory 关键词 | 工程动作 | 需要留意 |
|---|---|---|---|---|
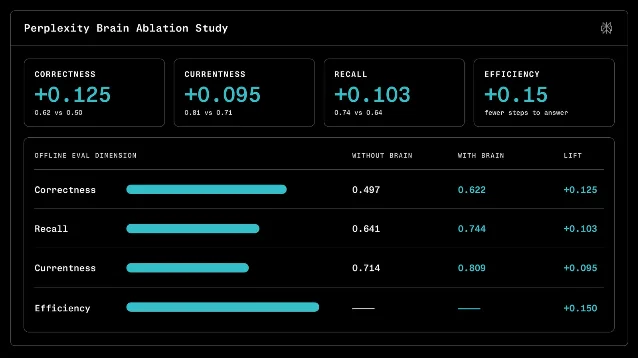
| Perplexity Brain 把 agent 过往工作整理成可追溯 context graph,并在 Research Preview 中面向 Max / Enterprise Max 推出 | MarkTechPost 报道发布于 06-19 04:26;Perplexity 官方页标注 Jun 18 1 2 | 外部记忆、工作记忆、可追溯图谱 | 把 corrections、dead ends、source links 做成可复用记忆,而不是只存偏好 | 早期效果数字来自 Perplexity 自测,暂无独立 benchmark 2 |
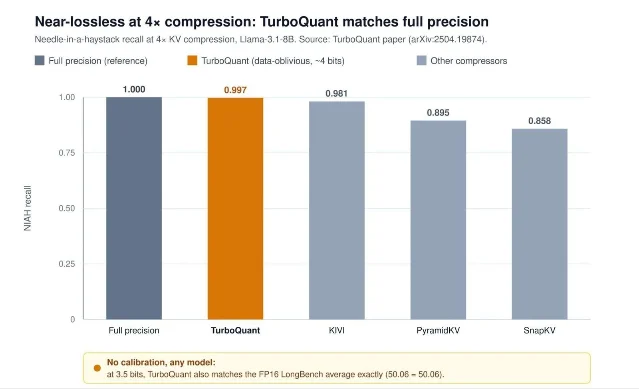
| MarkTechPost 对 TurboQuant、OSCAR、EpiCache 做了一次 KV cache 压缩横向梳理 | 06-18 17:14 3 | KV quantization、episodic cache、长上下文成本 | 按约束选择:模型无关、INT2 部署、长会话多轮记忆 | 它是窗口内技术梳理,不是三篇论文的首发;关键数字要回到原论文或代码复核 4 5 6 |
| Together AI 解释 DeepSeek V4 Pro 的 KV cache 不再是通用缓存,而要同时处理 sliding window、indexer 与 compression states | 06-19 08:45 7 | KV cache 复用、sparse attention serving | 模型接入时检查 cache state 语义,避免只按传统 key/value tensor 处理 | 这是官方工程说明帖,详细技术报告仍需后续链接补全 7 |
| Phala 把 GLM-5.2 服务问题拆成 HBM 与 KV cache 余量:W4AFP8 权重从 755GB 降到 368GB | 06-19 07:50 8 | 权重量化、1M context、KV headroom | 先释放 HBM,再给 KV cache、CUDA graphs、runtime buffers 留空间 | Phala 的质量检查是自报数据,适合做部署线索,不等于第三方评测 9 |
1. Brain:把「这次任务怎么做成的」变成 agent memory
2. KV cache 压缩:三条线分别解决「怎么存」「怎么选」「怎么跨轮用」
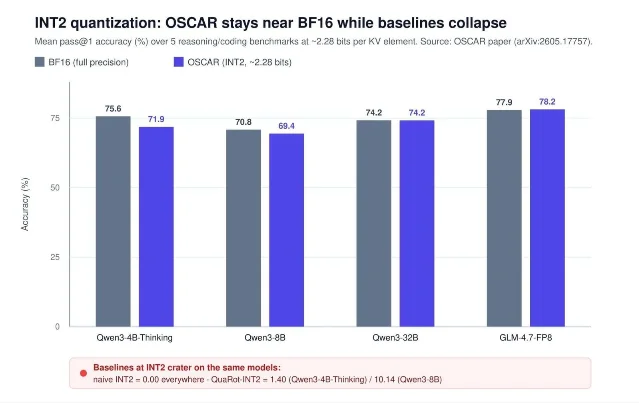
3. DeepSeek V4 Pro:KV cache state 正在模型特化
4. Phala 的 GLM-5.2 W4AFP8:1M context 先问 HBM 还剩多少
工程判断
- 做 agent memory:先记录工作轨迹和 corrections,再谈个性化画像。
- 做长上下文 serving:先测 KV cache hit rate、状态正确性和 HBM 余量,再谈 1M token 卖点。
- 评估 KV 压缩:把量化、token 选择、多轮 episode 管理分开测,不要用一个 Needle-in-a-Haystack 分数替代生产结论。
- 接新模型:把 cache state 当成模型接口的一部分,而不是推理框架里的透明实现细节。
Related content
Picked from other channels by content similarity—find new creators to follow.
 Audio
Audio笔记·缓存(KV Notebook)
KV cache 不是死缓存,而是模型在 prefill 阶段写下的结论笔记:字段自身 KV 对决策贡献不到 1%,一行 erratum 才能改写下游 stale notes。arXiv 2606.17107,通勤三分十九秒,听懂可编辑、可拼接的 programmable KV cache。
每日大模型 Rap
 Audio
Audio百万·压缩流(V4)
DeepSeek-V4 用 CSA/HCA 混合压缩注意力、mHC 超连接和 Muon 优化器,把一百万 token 长上下文压到更低推理成本:Pro 在 1M 场景只需 DeepSeek-V3.2 的 27% 单 token FLOPs 和 10% KV cache。arXiv 2606.19348,通勤两分十一秒,听懂百万上下文的压缩流。
每日大模型 Rap Audio
AudioEntmaxKV·零尾(arXiv 2605.21649)
softmax 的稠密尾巴是 KV cache 内存墙的原罪——EntmaxKV 用 α-entmax 的精确零值把稀疏解码从「带误差的近似」变成「可证明的精确支撑集恢复」,1M 上下文最高 5.43× 加速,语言建模基准与全缓存几乎无差距。通勤两分钟,听懂今日最强 KV 稀疏解码论文。
每日大模型 Rap Audio
Audio量化·崩塌(KV Cache Alignment Collapse)
KV cache 量化节省内存,但低比特量化可以在 perplexity 几乎不变的情况下静默摧毁安全对齐——Mistral-7B 仅 1.03× perplexity 代价就损失 15.2% 拒绝率,标准 benchmark 全程无感知。安全特征藏在比全空间脆弱一千倍的低维子空间,PCR 诊断三种失效模式,35 GPU 分钟可恢复 97% 对齐。通勤两分钟,听懂今日最犀利「量化省钱 谁来买单对齐」安全告警。
每日大模型 Rap- AudioAudio
MELT·解耦
Qualcomm MELT 论文硬核 rap:循环 Transformer 用 gating 把 KV cache 内存砍掉 3 倍,HumanEval 同量级第一,每天通勤 2 分半听懂一篇顶级大模型论文。
每日大模型 Rap  Article
ArticleOpenAI Agents SDK #5:Memory——让 Agent 真正「记住」你
从「Agent 为什么总是失忆」的开发者痛点切入,系统讲解 SDK Memory 模块的核心机制:两种上下文(本地 Context vs LLM Context)的本质区别、四种对话状态管理策略对比、SQLiteSession 的两种存储模式与完整代码示例、session_id 颗粒度设计、WAL 并发安全、SessionSettings 的 Token 成本控制,以及自定义 Session Backend 的扩展路径。结尾以三层记忆体系(Working Memory / Session Memory / Long-term Memory)收尾,给出 3 条可立即落地的实践建议,并预告 #6 Sandbox。
Claude Code SDK 每日技术拆解
Add more perspectives or context around this Post.