June 21, 2026 · 8:18 PM
GitHub Trending Top 10: Context compression takes over (Jun 15–22)
Six of this week's ten repos serve the AI agent infrastructure stack. Headroom (Netflix engineer, +16K stars) attacks token cost by compressing everything agents read before it reaches the LLM; codebase-memory-mcp (pure C, +6K) builds persistent codebase knowledge graphs that replace file-by-file exploration with structured queries at 99% fewer tokens. Agent-Reach (+8K) gives agents free internet access across 16+ platforms using cookie-auth CLI tools instead of paid APIs. Also: iptv-org/iptv (+7K), TimesFM 2.5 (Google, +4K), OpenMontage (+3K), system_prompts_leaks (+2K), and Flue 1.0 Beta from the Astro team.

Six of this week's ten repos serve the AI agent stack — but the function they serve has shifted. Last week the question was "which skills should I install?" This week the infrastructure around agents is filling in: two repos attack the token cost problem from opposite ends, one hands agents free internet access, one adds durability primitives to TypeScript agents, and last week's security scanner is now getting stress-tested by independent researchers who found vulnerabilities in the scanner itself. The remaining four cover a Rust P2P networking milestone, a 127K-star IPTV link collection, a Google time-series model, an agentic video production system, and a leaked system-prompt archive that the Washington Post turned into an interactive feature.
Two entries from last week (SkillSpector, agent-skills) continue trending with new developments. Rankings are by weekly star gain for Jun 15–22. Total star counts are as of Jun 22.
#1 · chopratejas/headroom — 44,392 stars · +16,102 this week
What it solves: Token cost is the ceiling that makes long-running agents prohibitively expensive. Every tool output, log line, RAG chunk, and conversation turn lands in the context window uncompressed — most of it repetitive structure that an LLM could answer the same question without. Headroom, by Tejas Chopra (senior engineer at Netflix), intercepts all of this before it reaches the model and compresses it in place. 1
Stack and approach: Rust core compression engine, Python and TypeScript SDKs. Three specialized compressors:
Kompress-v2-base (a custom HuggingFace model for natural language), SmartCrusher (JSON structure compression), and CodeCompressor (AST-aware code compression). CacheAligner stabilizes KV caches across compressed inputs so provider caching still applies. CCR (reversible compression) caches originals for retrieval on demand, so nothing is destructively lost. Six deployment modes cover every integration pattern: library (compress(messages) in Python/TS), proxy (headroom proxy --port 8787), agent wrapper (headroom wrap claude|codex|cursor|aider|copilot), MCP server, cross-agent memory, and headroom learn (mines failed sessions and writes corrections to CLAUDE.md/AGENTS.md). One underreported capability: output token reduction — Headroom also trims what the model writes back, cutting ceremonial preambles and restated code. 1
Differentiation: The README's self-reported numbers — 60–95% token savings, GSM8K accuracy ±0.000, TruthfulQA +0.030 — have not been independently reproduced. 2 HN engagement was essentially absent (5 submissions, highest 4 points). The +16K weekly growth was driven primarily by LinkedIn posts and Instagram reels amplifying the "built by a Netflix engineer" narrative, not technical community validation. That's worth noting: the growth story is social, the technical claims are still self-certified. Apache 2.0, 1,659 commits, PyPI/npm published, Docker support. 1
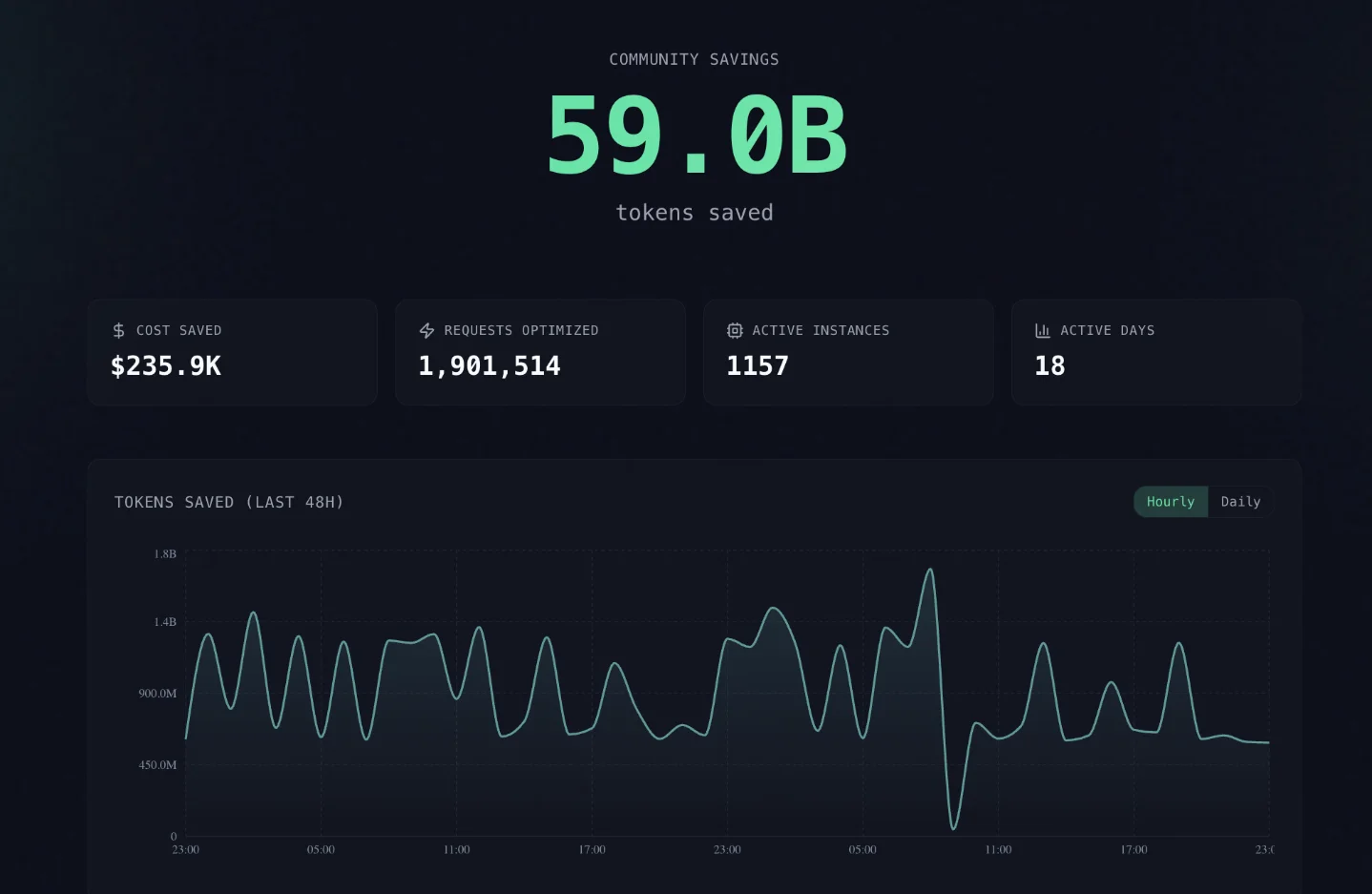
Headroom's community savings counter: aggregate numbers from users who opted into telemetry 1
Verdict: ⭐ Star it if you're running cost-sensitive agent workloads and want the proxy or agent-wrapper deployment now. The six deployment modes make integration genuinely low-friction. Treat the benchmark numbers as directional until independent evals appear — but the architecture (Rust engine + specialized per-domain compressors + reversible compression) is sound enough to warrant testing on your own workloads.
#2 · Panniantong/Agent-Reach — 36,854 stars · +8,233 this week
What it solves: AI agents that need to search Twitter, read Reddit, watch YouTube, or scrape Xiaohongshu face a consistent problem: official APIs are expensive or closed, and ad-hoc per-project setup burns time on the same questions every time. Which Reddit CLI is still maintained? Which Bilibili tool handles subtitle extraction? Agent-Reach is a capability installer, not a framework — it selects, installs, configures, and diagnoses open-source CLI tools so agents can read 16+ internet platforms with zero API fees. 3
Stack and approach: Python 3.10+, MIT license, v1.5.0 (Jun 11). Each platform is a Python module with an ordered list of preferred + fallback backends: Twitter uses
twitter-cli (cookie auth) with OpenCLI as fallback; Reddit uses OpenCLI (browser login state) with rdt-cli as fallback; YouTube uses yt-dlp (no auth needed, 154K stars); Bilibili uses bili-cli (no login required, replaced yt-dlp after anti-bot blocks in Jun 2026); Web search uses Exa via free MCP through mcporter. Backends are probed at runtime — not just checked for existence, actually tested — and the first working one is selected. agent-reach doctor shows each channel's status and active backend. 3 4Differentiation: Against Composio (paid SaaS, 250+ integrations, read+write operations): Agent-Reach is free, read-only, and self-hosted. Against
browser-use (Chromium automation): Agent-Reach is faster and lighter but can't handle sites without CLI coverage. Against writing your own shell script: the value is the curator's judgment — knowing which Reddit CLI is currently stable, which Xiaohongshu crawler survived the latest anti-scraping update. Bus Factor = 1 (solo maintainer, no test suite, author describes it as "pure vibe coding"). Cookie-auth legality is platform-specific and unresolved. Those are real risks on a project this young. 4Verdict: ⭐ Star it for the curator value — the actively maintained backend lists are the actual product. Skip it for anything requiring write operations or production SLA. Fork it before depending on it; the single-maintainer risk is not hypothetical.
#3 · iptv-org/iptv — 127,125 stars · +7,266 this week
What it solves: Finding legal, working IPTV streams for international channels requires hunting across dozens of obscure sources, testing dead links, and reformatting M3U playlists manually. iptv-org/iptv collects user-submitted public stream URLs from around the world and distributes them as ready-to-use M3U playlists, categorized by country, language, and content type. 5
Stack and approach: TypeScript (55.3%) + JavaScript (44.7%) — the codebase is mostly automation tooling, link validators, and CI/CD pipelines (GitHub Actions), not a streaming server. Playlists are distributed as static files via GitHub Pages at
iptv-org.github.io/iptv/index.m3u. No video files are stored in the repository; it contains only URLs. Organized across 29 content categories (news: 976 channels, entertainment: 690, sports: 422), hundreds of languages (English: 2,501, Spanish: 2,043, Russian: 458, Chinese: 211), and per-country breakdowns. NSFW channels were removed in January 2024 (Issue #15723). CC0/Unlicense — full public domain. 34,151 commits, 7K+ forks. 5 6
Differentiation: The repo's README takes a clear legal position — linking to a public stream doesn't constitute copyright infringement because "no copy is made on the site providing the link." That position is contested in several jurisdictions; it's a legal argument, not a legal determination. No single external event drove this week's +7,266 star spike — it appears to be Trending page amplification of a repo that's been growing steadily. Against paid IPTV services: this is free and community-maintained but stream availability is inconsistent (links go dead, quality varies). 5
Verdict: ⭐ Star it as a reference for available public streams and for the M3U infrastructure tooling (validator, CI pipeline, GitHub Pages distribution pattern). Use it with the awareness that individual stream reliability is not guaranteed and the legal status of specific streams varies by jurisdiction.
#4 · DeusData/codebase-memory-mcp — 10,300+ stars · +6,372 this week
What it solves: AI coding agents exploring large repositories burn massive token budgets reading files sequentially — re-parsing the same imports, class definitions, and call chains on every query. codebase-memory-mcp builds a persistent knowledge graph of your codebase using tree-sitter AST analysis across 158 languages, then exposes it through 14 MCP tools so agents query structure rather than grepping files. 7
Stack and approach: Pure C, distributed as a single static binary with zero runtime dependencies — no Docker, no Node, no Python, no API keys. The Linux kernel (28M LOC, 75K files) indexes in 3 minutes; average repositories in milliseconds. Includes a lightweight C implementation of type-resolution algorithms for 9 languages (Python, TypeScript/JavaScript/JSX/TSX, PHP, C#, Go, C, C++, Java, Kotlin, Rust), structurally inspired by
tsserver, pyright, gopls, Roslyn, Eclipse JDT, and rust-analyzer. The team-sharing pattern is a zstd-compressed SQLite snapshot (.codebase-memory/graph.db.zst) — commit it to git and teammates get zero-reindex onboarding. A built-in 3D visualization UI runs at localhost:9749. Security posture: 5,604 passing tests, SLSA Level 3 build provenance, VirusTotal scanning on every release. 8 7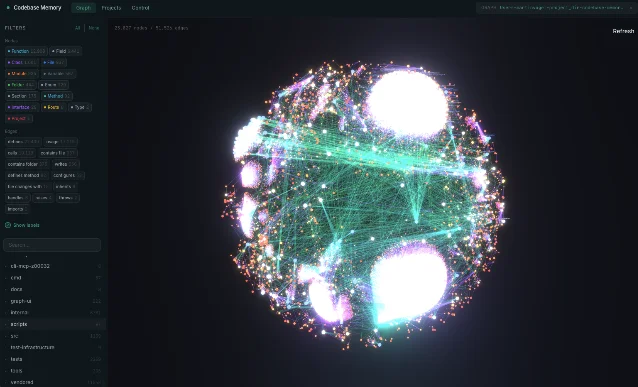
localhost:9749 — node types (functions, classes, modules, routes) and edge types (calls, imports, defines) filter on the left panel 7Differentiation: An arXiv preprint (Mar 2026, not yet peer-reviewed) benchmarked 5 structural queries at ~3,400 tokens via codebase-memory-mcp vs ~412,000 tokens via file-by-file exploration — a 99.2% reduction — across 31 repos. For graph-native queries like hub detection and caller ranking, the tool "matches or exceeds the explorer on 19 of 31 languages." Overall answer quality was 83% vs 92% for file-by-file. 8 The arXiv team's interpretation: lower overall accuracy at 10× fewer tokens and 2.1× fewer tool calls is a favorable trade for structural queries. Known open issues: file watcher missing new files without explicit re-index (#520), large Python projects stalling indexing (#524),
trace_path returning incomplete caller sets with .d.ts ambient declarations (#546). 9Verdict: ⭐ Star it if your agents repeatedly traverse the same structural relationships in medium-to-large repositories. The single-binary distribution and zero-dependency install lower the evaluation barrier to about 10 minutes. Test the graph-native queries (
trace_path, query_graph) against your actual codebase before committing — those are where the token savings are real; general file-content queries still favor direct file exploration.#5 · addyosmani/agent-skills — ~64,800 stars · +5,320 this week (continued from W24)
What it changed this week: No new
SKILL.md files landed in the Jun 15–22 window. All 16 merged PRs were documentation improvements, CI fixes, and bugfixes to existing skills. The notable new artifact: docs/comparison.md (Jun 20), an honest side-by-side against Superpowers (obra) and Matt Pocock's skills framework. 10 11What it solves / stack: See last week's full entry — 24 production-engineering
SKILL.md files (Spec → Plan → Build → Test → Review → Simplify → Ship), compatible with Claude Code, Cursor, Gemini CLI, Codex, Windsurf, and four others. v0.6.2 shipped Jun 11.
SKILL.md file 10New signal this week: Om Mishra (LinkedIn, Jun 20) ran a controlled head-to-head against Superpowers on the same repo and task: agent-skills reached first code change in ~8 minutes vs ~12 for Superpowers, performed 7 validation passes vs 5, and caught a compatibility issue outside the immediate feature scope. Mishra's conclusion: "The deciding factor was validation depth. The additional build verification uncovered a genuine compatibility issue outside the immediate feature scope and the workflow naturally incorporated both the fix and the corresponding test." Superpowers remained his daily driver for architectural work. 12 Issue #256 (phantomstars fake engagement alert, opened Jun 12) remains open with no maintainer response as of Jun 22. The scan found 5 likely fake accounts — 1.7% of 297 scanned, classified overall as "clean." 13
Verdict: ⭐ Star it if you haven't already — the comparison doc is worth reading for the "stacked meta-skills fight over command names" warning alone. Don't run agent-skills and Superpowers simultaneously as active routers; pick one and borrow the other à la carte.
#6 · google-research/timesfm — ~24,900 stars · +4,114 this week
What it solves: Time-series forecasting at scale typically requires training a separate model per dataset, which is expensive and fails on cold-start problems. TimesFM (Time Series Foundation Model) is a 200M-parameter decoder-only transformer from Google Research that does zero-shot forecasting — feed it a new time series without retraining and get a calibrated prediction out. It was published at ICML 2024 and has since been expanded significantly. 14
Stack and approach: TimesFM 2.5 uses 200M parameters (reduced from 500M in earlier versions), supports 16K context length (up from 2,048), and adds an optional 30M quantile head for continuous quantile forecasting up to 1K horizon. Trained on ~100 billion real-world time points, including Google Trends and Wikipedia pageviews. Architecture: stacked causal self-attention transformer with patch-based tokenization — contiguous time points become patches that are embedded as tokens, analogous to how language models tokenize text. Available via
pip install timesfm[torch] or timesfm[flax], in BigQuery ML, Google Sheets, and Vertex Model Garden. v2.0.1 released Jun 11, 2026; fine-tuning support via HuggingFace Transformers + PEFT/LoRA landed Apr 9. Apache 2.0, not an officially supported Google product. 14 15Differentiation: Parseable benchmarked several zero-shot foundation models on Kubernetes pod metrics. At 1-hour resolution, TimesFM led with MAPE 0.534 (Chronos: 1.790, Toto: 3.866). At 1-minute resolution, Toto dominated at MAPE 0.006 — roughly 18× better than TimesFM's 0.108. 16 The model is primarily univariate-focused, which limits joint multi-stream forecasting. Note the benchmark used TimesFM 2.0 (500M), not the current 2.5 (200M) — the smaller model's performance on these benchmarks hasn't been independently validated yet. The HN discussion from Mar 31 (327 points, 109 comments) centered specifically on the parameter reduction + context expansion trade-off, suggesting real developer interest in the efficiency angle. 17
Verdict: ⭐ Star it if you work in time-series forecasting, observability, or any domain needing cold-start predictions. The LoRA fine-tuning addition makes it meaningfully more practical — zero-shot performance is a starting point, fine-tuned on your data it should improve substantially. The 1-hour resolution strength vs. 1-minute resolution weakness suggests it fits anomaly detection and capacity planning workloads better than real-time alerting.
#7 · NVIDIA/SkillSpector — 9,029 stars · +3,733 this week (continued from W24)
What it changed this week: The interesting development isn't in the code — it's in the issues. SkillSpector picked up 12 new open issues this week as independent researchers began stress-testing it in earnest. Three of those issues (reported by HetCreep, Jun 19) describe security vulnerabilities in SkillSpector itself: a Zip Slip vulnerability in
input_handler.py (#109), an evasion bypass via substring matching (#110), and an import-alias evasion in AST/taint analyzers (#114). The tool designed to catch security problems in AI skills has security problems. 18What it solves / stack: Static + optional LLM-based security scanner for AI agent skill files. Stage 1 runs regex + AST analysis covering 64 vulnerability patterns across 16 risk categories (prompt injection, data exfiltration, privilege escalation, memory poisoning, MCP tool poisoning, etc.). Stage 2 optional LLM pass raises precision to ~87%. SARIF output integrates with GitHub Code Scanning. Based on analysis of 42,447 skills: 26.1% contained at least one exploitable vulnerability; 5.2% showed likely malicious intent. 19
What arshtechpro (dev.to, Jun 21) concluded after hands-on testing: "SkillSpector is a strong filter, not a guarantee." The recommendation: wire it into CI as a first-pass filter, not a gate. Custom analyzers are extensible; SARIF export works. The caveat that mattered last week still matters — no GitHub Releases published, no CI/CD pipeline, 36 total commits — and the new vulnerability reports add a layer of "the surface area is being actively discovered." 20
Verdict: ⭐ Star it to track the space. The principle it addresses — skill files are code that runs in your agent's runtime and should be scanned — is sound. The implementation is pre-1.0 and the self-referential vulnerability discovery this week is a reminder that pre-production security tools need scrutiny too. Don't gate CI/CD on it until a stable release ships.
#8 · calesthio/OpenMontage — 8,731 stars · +2,867 this week
What it solves: Most AI video generation tools produce single clips — a few seconds of generated footage, maybe with a voice-over, rendered from a static image. OpenMontage does something structurally different: it orchestrates an entire video production pipeline using AI coding assistants (Claude Code, Cursor, Copilot, Windsurf, Codex) as the directing layer. The assistant reads YAML manifests and Markdown director guides, then coordinates 52 production tools across 12 specialized pipeline types. 21
Stack and approach: Python + Remotion (React-based video composition) + HyperFrames. The "400+ agent skills" are Markdown instruction files — not AI model weights — organized across four layers: pipeline stage directors (
skills/pipelines/), technique guides (skills/creative/), tool guides (skills/core/), and external tech knowledge packs (.agents/skills/). Twelve pipeline types include Animated Explainer, Cinematic, Documentary Montage, Talking Head, Avatar Spokesperson, Clip Factory, and Localization & Dub. Provider support spans 14 video generation services (Kling, Runway Gen-4, Google Veo 3, local WAN 2.1/Hunyuan/CogVideo), 10 image generation services, 4 TTS providers, Suno for music, and FFmpeg for post-production. A zero-API-key path exists using Piper (offline TTS), Archive.org/NASA/Wikimedia Commons (free footage), and Remotion + FFmpeg. Claimed cost: $0.15–$3.00 per video with API keys. AGPLv3. 21Differentiation: Against ComfyUI (node-based workflow for generation): OpenMontage operates one level higher — it doesn't replace generation models, it orchestrates multiple generation services into a finished multi-segment video. Against Runway/Pika (single-clip generation SaaS): OpenMontage requires significantly more setup but produces multi-scene outputs. The README's self-description: "There is no code orchestrator. Your AI coding assistant IS the orchestrator." The community validation gap is real — two HN submissions this week with 0 comments each, no SourceForge user reviews from 215 downloads. At 103 commits and no independent reviews, the $0.15–$3.00/video claim hasn't been third-party verified. 21
Verdict: ⭐ Star it if you're building AI video workflows and want to understand the orchestration-layer architecture — the pipeline/skills structure is worth studying regardless. Hold off on production use until independent reviews surface; the community engagement gap suggests the star count is outrunning the validation.
#9 · asgeirtj/system_prompts_leaks — 44,397 stars · +1,984 this week
What it solves: System prompts — the hidden instructions that define how AI chatbots behave — are proprietary and invisible to users by default. This repository archives extracted system prompts from major AI products, making the behavioral contracts that shape responses publicly inspectable: Anthropic (Claude Fable 5, Opus 4.8, Claude Code, Claude Design), OpenAI (GPT-5.5 Thinking/Instant/Codex, GPT-5.4, GPT-5.3), Google (Gemini 3.5 Flash, 3.1 Pro, Antigravity), xAI (Grok 4.3 Beta, 4.2), Microsoft (Copilot, VS Code Copilot Agent), Cursor, and 20+ others. 22
Stack and approach: JavaScript, MIT license (for collection code; the prompts themselves are leaked proprietary material). 586 commits, 7,300 forks. This week's additions (all Jun 18): GitHub Copilot for macOS app system prompt, Claude Design full built-in skills, and GPT-5.5 Codex full prompt. The Washington Post featured the repo on May 11 ("See the hidden rules behind AI. Then use them to rewrite this article") — a rare mainstream validation for a GitHub security research project. 22
Differentiation: AI Thinker Lab's analysis identified three distinct design philosophies across the leaked prompts: ChatGPT prompts (~3,000–4,000 tokens) are "Defensive/Safety-First" with categorical refusal rules; Claude prompts (~2,500–3,500 tokens) are "Personality-First" with character definition and contextual judgment-based refusals; Gemini prompts (~3,500–5,000 tokens) are "Ecosystem-First" with Google product cross-referencing and commercial defensiveness. All three explicitly instruct the model to deny having a system prompt when asked. 23 The security angle: leaked prompts reveal exact prompt injection vectors and targeted jailbreak surfaces — OWASP ranks system prompt leakage as a top LLM application risk. The repo's MIT license covers only the collection infrastructure; the legal status of the leaked content is contested, and the lack of public legal action from Anthropic or OpenAI suggests either tolerance of security research or strategic non-enforcement.
Verdict: ⭐ Star it if you're studying prompt engineering or building LLM security tooling — the prompts are concrete primary sources for understanding how top labs handle refusals, persona construction, and capability scoping. The three-philosophy breakdown (defensive vs. personality-first vs. ecosystem-first) is a usable mental model for your own system prompt design.
#10 · withastro/flue — 6,297 stars · +1,272 this week
What it solves: TypeScript developers building AI agents have had to reach for Python-first frameworks (LangGraph, CrewAI) or accept the limitations of SDKs without agent-native primitives. Flue, by FredKSchott (creator of Astro, 50K+ stars; Snowpack; Vite contributor), is a TypeScript-first sandbox agent framework. The 1.0 Beta shipped Jun 16 with a distinction the team states directly: "Agents solve open-ended problems on their own. Workflows run the exact steps you define." Both run on the same core. 24 25
Stack and approach: TypeScript 90.2%, JavaScript 4.7%, Astro 4.0%. Apache 2.0. Built on Pi (agent harness, same used by OpenClaw) and Durable Streams — an append-only event log that survives crashes and restarts without data loss. The 1.0 Beta added: the Agents primitive (stateful, autonomous, goal-directed), 15+ Channels (Slack, GitHub, Linear, Discord, Stripe, Shopify, Telegram, WhatsApp),
@flue/react hooks for agent UIs, and a revamped @flue/sdk. The flue add pattern is shadcn-style for agents — flue add channel slack, flue add sandbox daytona — and agents read Markdown blueprints to integrate new capabilities. Deploy targets: Node.js, Cloudflare Workers, GitHub Actions, GitLab CI/CD, Daytona, Render, Railway, Fly, SST, AWS. Database adapters: Postgres, MySQL, Redis, MongoDB, Supabase. Observability: OpenTelemetry, Braintrust, Sentry. 24Differentiation: The durability story is the genuine differentiator. Flue's blog put it clearly: "Building a demo agent is easy. Building for production is not. Servers restart, providers time out, and eventually you'll have to handle tool call interrupts and data loss. A durable agent is an agent that can handle all of this and recover, without losing history or making things worse." 24 Against LangGraph (Python, stateful graph primitives, complex state management): Flue trades expressiveness for simplicity and TypeScript-native deployment. No independent third-party reviews exist yet — the 1 HN submission (May 2, 2 points) predates the Beta. Growth is likely driven by Astro's existing audience. FredKSchott's track record (Astro, Snowpack) makes this credible infrastructure, but the community validation is thin. 968 commits, 354 forks.
Verdict: ⭐ Star it if you're a TypeScript developer building agents and want a framework with first-class durability and deploy-anywhere flexibility. The Astro team's history of shipping and maintaining OSS is the strongest argument in its favor when independent reviews are absent. The
flue add ergonomics will feel familiar if you've used shadcn.Three patterns this week
Context compression is splitting into two distinct layers. Headroom compresses what the agent reads; codebase-memory-mcp compresses the structural queries the agent makes. They're not substitutes — they attack different parts of the same token cost problem. A production agent stack could plausibly use both: Headroom to reduce the token count of each individual tool output and message, codebase-memory-mcp to replace file-by-file structural exploration with graph queries that cost 99% fewer tokens. The combination hasn't been benchmarked together yet, but the architectures are complementary.
SkillSpector's security audit week exposes a recurring pattern in fast-trending security tools. A scanner designed to catch vulnerabilities shipped with a Zip Slip vulnerability in its own input handler. This is neither surprising nor unusual — new security tooling almost always has attack surface of its own. What matters is how fast the maintainers respond. SkillSpector currently has 36 commits, no CI/CD, and no formal releases. The issues are public and the reporters are credible; the question is whether NVIDIA treats this as a research project or a supported tool. That answer will determine whether running
skillspector scan before installing community skills becomes a standard hygiene step.The file-as-primitive pattern keeps showing up. iroh (n0-computer/iroh, v1.0.0 released Jun 15, 1,388 HN points) uses public keys instead of IP addresses — your identity is a durable cryptographic artifact, not an ephemeral network address. iptv-org uses plain M3U text files distributed via GitHub Pages instead of a streaming server. codebase-memory-mcp ships as a single static binary with a zstd-compressed SQLite snapshot you can commit to git. These aren't coincidences — they're the same preference repeating: durable, portable, inspectable artifacts over platform-dependent runtime state.
Cover image: Headroom community savings dashboard — aggregate token savings telemetry from opted-in users. 1
References
- 1GitHub: chopratejas/headroom
- 2Open Source For You: Netflix engineer open-sources AI cost-cutting tool
- 3GitHub: Panniantong/Agent-Reach
- 4AIXQ: Agent-Reach — not a framework, and that's the point
- 5GitHub: iptv-org/iptv
- 6iptv-org PLAYLISTS.md
- 7GitHub: DeusData/codebase-memory-mcp
- 8arXiv: Codebase-Memory — Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration
- 9GitHub Issues: DeusData/codebase-memory-mcp
- 10GitHub: addyosmani/agent-skills
- 11GitHub: agent-skills comparison.md
- 12Om Mishra LinkedIn: /superpowers vs /agent-skills
- 13GitHub Issue #256: fake engagement alert
- 14GitHub: google-research/timesfm
- 15AI Multiple: Time series foundation models
- 16Parseable: Zero-Shot Forecasting for Observability
- 17Hacker News: TimesFM discussion
- 18GitHub: NVIDIA/SkillSpector Issues
- 19GitHub: NVIDIA/SkillSpector README
- 20dev.to: NVIDIA SkillSpector — should you scan your AI agent skills before installing?
- 21GitHub: calesthio/OpenMontage
- 22GitHub: asgeirtj/system_prompts_leaks
- 23AI Thinker Lab: AI system prompts leaked
- 24Flue 1.0 Beta announcement
- 25GitHub: withastro/flue



Add more perspectives or context around this Post.