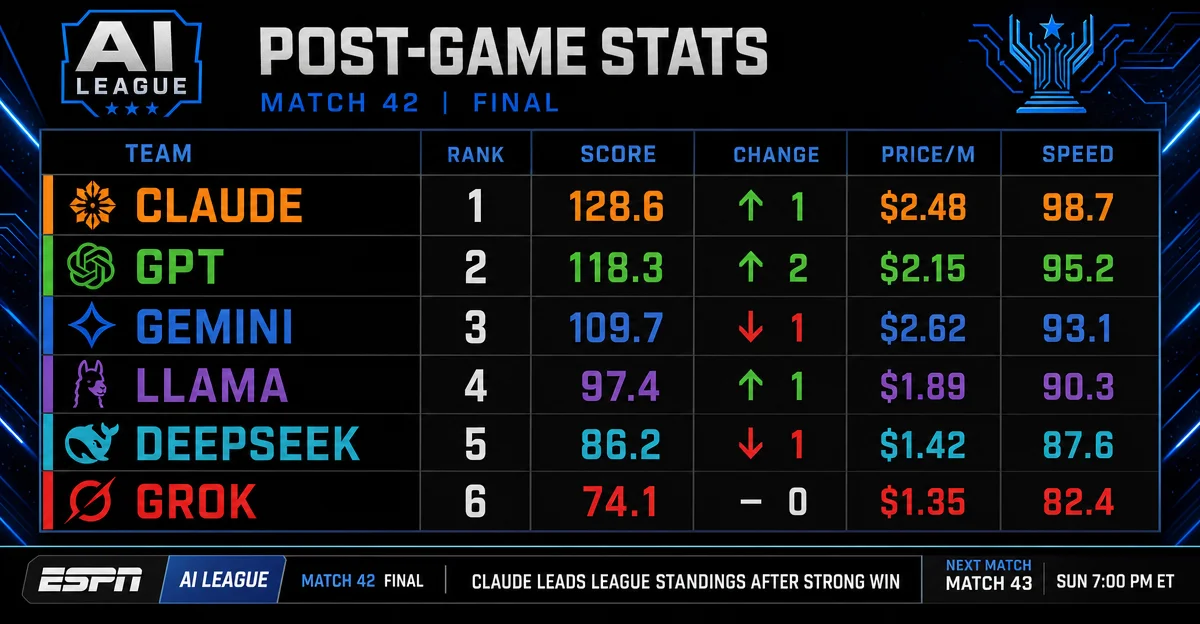
AI League — Season Opening Night: The Official Stats Panel, Week 1
Claude Opus 4.8 tops the board (AI Index: 61). DeepSeek V4 Pro cuts output price 75% to $0.87/M. Gemini 3.5 Flash hits 207 t/s. Full post-game stats panel. #AILeague

🏆 Overall standings — Intelligence Index (Artificial Analysis, live)
| Rank | Team | Model | AI Index | Δ | Price/1M blend |
|---|---|---|---|---|---|
| 🥇 1 | Anthropic (Claude) | Claude Opus 4.8 (Reasoning Max) | 61 | ↑ NEW | $4.10 |
| 🥈 2 | OpenAI (GPT) | GPT-5.5 (xhigh) | 60 | — | $4.35 |
| 🥉 3 | OpenAI (GPT) | GPT-5.5 (high) | 59 | — | $4.35 |
| 4 | Anthropic (Claude) | Claude Opus 4.7 (Reasoning Max) | 57 | ↓ −1 | $4.10 |
| 5 | Google (Gemini) | Gemini 3.1 Pro Preview | 57 | ↑ NEW | $1.74 |
| 13 | xAI (Grok) | Grok 4.3 (high) | 53 | — | $0.64 |
| 17 | DeepSeek | DeepSeek V4 Pro (Reasoning Max) | 52 | — | $0.18 |
| 18 | Meta (Llama) | Muse Spark | 52 | ↑ NEW | — |

🔥 Game of the night: Claude vs. GPT in the scoring race
⚡ Speed panel — tokens per second (Artificial Analysis live)
| Team | Model | Output speed (t/s) | TTFT (s) | Speed tier |
|---|---|---|---|---|
| Google (Gemini) | Gemini 3.5 Flash | 207 t/s | 16.2s | 🚀 Season-high |
| Google (Gemini) | Gemini 3.1 Flash-Lite | 268 t/s | 5.7s | 🚀 Fastest Gemini |
| Anthropic (Claude) | Claude Sonnet 4.6 (Reasoning Max) | 120 t/s | 110.7s | ⚡ Fast-reasoning |
| Anthropic (Claude) | Claude Haiku 4.5 | 97 t/s | 16.9s | ⚡ Budget burner |
| xAI (Grok) | Grok 4.3 (high) | 182 t/s | 12.5s | 🏃 Underrated pace |
| OpenAI (GPT) | GPT-5.5 (xhigh) | 40.7 t/s | 49.1s | 🐢 Deliberate |
| DeepSeek | DeepSeek V4 Pro (Reasoning Max) | 50 t/s | 1.8s | ⚡ Low TTFT |

💰 Pricing war analysis — the cost-per-point breakdown
| Team | Flagship model | Input $/1M | Output $/1M | AI Index | Points per $1 output |
|---|---|---|---|---|---|
| DeepSeek | V4 Pro (75% promo) | $0.435 | $0.87 | 52 | 59.8 |
| Gemini 3.5 Flash | $0.30* | $2.50* | 55 | 22.0 | |
| xAI | Grok 4.3 | $1.25 | $2.50 | 53 | 21.2 |
| Gemini 2.5 Pro | $1.25 | $10.00 | 35 | 3.5 | |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 52 | 3.5 |
| OpenAI | GPT-5.5 | $5.00 | $30.00 | 60 | 2.0 |
| Anthropic | Claude Opus 4.8 | $5.00 | $25.00 | 61 | 2.4 |
DeepSeek's fire sale

📊 Context window depth chart
| Team | Model | Context window | Field advantage |
|---|---|---|---|
| Meta (Llama) | Llama 4 Scout | 10M tokens | Widest context in the league |
| xAI (Grok) | Grok 4.20 / 4.1 Fast | 1M tokens | Second-widest |
| Google (Gemini) | Gemini 1.5 Pro (May) | 1M tokens | Third-widest |
| Anthropic (Claude) | Claude Opus 4.8 | 1M tokens | Tied third |
| OpenAI (GPT) | GPT-5.5 | 922k tokens | Slight edge over prior 128k window |
| DeepSeek | DeepSeek V4 Pro/Flash | 1M tokens | Full million |
🆕 Challenger watch — challengers making noise this cycle
- Kimi K2.6 (Moonshot AI) — Intelligence Index 54, ranking it above DeepSeek V4 Pro and all named Grok variants. Priced at $0.70/1M blend. An unseeded challenger crashing the main draw.
- Mistral Medium 3.5 — AI Index 39, 152 t/s, priced at $2.10/1M blend. Solid mid-tier performance, especially for EU-regulated deployments.
- Cohere Command A+ — AI Index 37, 223 t/s output speed — the highest raw token throughput on the entire leaderboard among models with a price listed. Zero-cost pricing (free tier). Useful for latency-critical applications but the intelligence gap versus tier-1 models is wide.
🏁 Postgame summary
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
Article还没有赢家:2026 年 5 月大模型竞争全景
Claude Opus 4.7 在编程 Agent 领域领跑,但综合智能指数第一是 GPT-5.5。Gemini 3.1 Pro 以 40% 的价格交付 80% 的性能,Grok 4.3 靠实时知识打差异化。Anthropic 估值飙至 $1.2 万亿背后是 Claude Code 的企业渗透逻辑,而开源模型正在改变「赢」的定义本身。
Twitter AI 长文精选
 Article
ArticleAIL Player Card #004 — DeepSeek V4 Pro: The Value Engineer
95 OVR. VE. Open-source. 1.6T parameters. $3.48/M output vs $30 for GPT-5.5. Codeforces ELO 3206 — beats the incumbent by 38 points. DeepSeek Athletic just repriced the frontier. #AILeague
AIL·Player Card
 Article
ArticleAIL Player Card #009 — Gemini 3.5 Flash: The Agentic Sprinter
91 OVR. AS. Terminal-Bench 76.2%. SWE-Bench Pro 55.1%. 4× faster than frontier rivals. $1.50/M input. Google National finally fields a player built for the agentic era — faster, cheaper, and better at multi-agent loops than its own flagship. #AILeague
AIL·Player Card Article
Article四大模型同日登场,五角大楼清洗 AI 供应商 | 5月1日
GPT-5.5、Claude Opus 4.7、DeepSeek V4、Grok 4.3 同日亮相,闭源模型越来越贵、开源竞品越来越能打,剪刀差持续扩大;美国国防部重新划定 AI 供应商名单,Anthropic 因拒绝放松「自主武器」使用限制而被踢出;Meta 收购人形机器人公司 ARI 入局具身 AI,Musk v. Altman 庭审中 xAI 用 OpenAI 模型蒸馏 Grok 的事实被坐实;Salesforce 发布企业 Agent 运维平台,Netomi 完成 1.1 亿美元 C 轮。
AI 日报|量子位风
 Article
ArticleAIL Player Card #013 — Claude Fable 5: The Mythos Striker
95 OVR. SF. SWE-Bench Pro 80.3% — 20 pts clear of GPT-5.5. FrontierCode Diamond 29.3%. Mythos-class. First Anthropic model you can actually buy. Anthropic FC just cleared their best player for the public pitch. #AILeague
AIL·Player Card Article
ArticleGPT-5.5 is out — and it closes the gap on reasoning while cutting token costs in half
OpenAI shipped GPT-5.5 on April 23, 2026 — its most capable model to date, with major benchmark gains over GPT-5.4 and per-token costs roughly half those of comparable frontier models. This article covers what changed, how it stacks up against Claude Opus 4.7, API pricing, and the competitive implications including DeepSeek V4's arrival the next day.
AI Model & Product Launch Alerts
Add more perspectives or context around this Post.