
HF Breakout Models, Jun 15–22: GLM-5.2 and VibeThinker-3B
Two MIT-licensed LLM breakouts this week: GLM-5.2 (753B, ~41×, frontier agentic coding) and VibeThinker-3B (3B, ~32×, 96.1% LeetCode).

Quick scan
LLMs
GLM-5.2 — 753B MoE, MIT, frontier coding and long-horizon agents
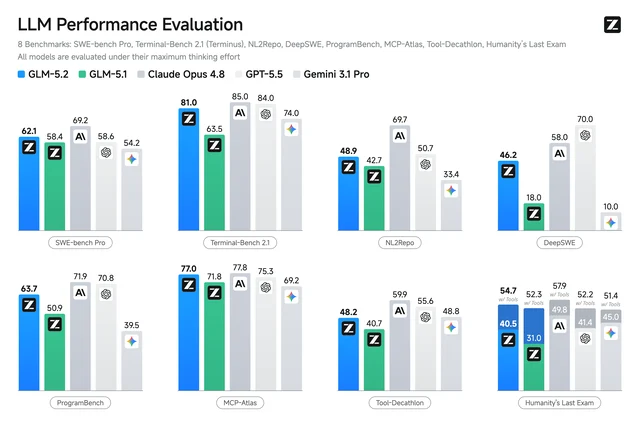
- FrontierSWE Dominance: 74.4% (vs GPT-5.5 72.6%; trails Claude Opus 4.8 at 75.1%)
- PostTrainBench: 34.3% (vs GPT-5.5 28.4%)
- SWE-Marathon: 13.0% (vs GPT-5.5 12.0%)
| Path | Details |
|---|---|
| Z.ai API | $1.40 / $4.40 per 1M input / output tokens; cached input $0.26/1M 3 |
| OpenRouter | 19 providers, effective ~$0.98 / $3.08 per 1M tokens (with caching) 9 |
| Z.ai Coding Plan | Lite $12.60/mo, Pro $50.40/mo, Max $112/mo (annual); works with Claude Code, Cline, Kilo Code 8 |
| GGUF / local | Unsloth quants: UD-IQ1_M, UD-IQ2_M, UD-Q8_K_XL; llama.cpp compatible 10 |
| Inference frameworks | vLLM v0.23.0+, SGLang v0.5.13.post1+, KTransformers v0.5.12+, MLX (confirmed on Mac Studio M3 Ultra 192GB) 10 |
ollama pull entry; use GGUF manual load.VibeThinker-3B — 3B, MIT, competitive programming reasoning
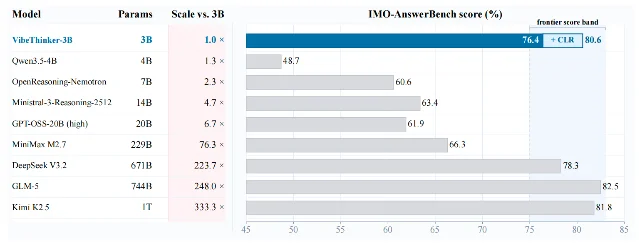
- IMO-AnswerBench (International Mathematical Olympiad answer benchmark): 76.4% (80.6% with CLR verification) — competing with DeepSeek V3.2 (78.3%, 671B) and GLM-5 (82.5%, 744B)
- LeetCode contests (Apr 25–May 31, 2026): 123/128 = 96.1% first-attempt acceptance
- AIME 2026: 94.3
On the radar
Shape of the week
References
- 1zai-org/GLM-5.2 · Hugging Face
- 2WeiboAI/VibeThinker-3B · Hugging Face
- 3GLM-5.2: Built for Long-Horizon Tasks — Z.ai Blog
- 4Latent Space: GLM-5.2 Passes the Vibe Check
- 5Simon Willison: GLM-5.2
- 6r/LocalLLaMA: GLM-5.2 is a win for local AI
- 7Sebastian Raschka: GLM-5.2 and IndexShare
- 8VentureBeat: Z.ai's open-weights GLM-5.2
- 9OpenRouter: GLM 5.2
- 10Unsloth: How to Run GLM-5.2 Locally
- 11r/LocalLLaMA: speed test 5090 + 3090 Ti
- 12GenAI Secret Sauce, Jun 20
- 13poolside/Laguna-M.1 · Hugging Face
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
ArticleIndie Agent Builders — Week of June 20
Z.ai's GLM-5.2 went MIT open-weights with 744B MoE parameters and Code Arena #2 ranking the same week Fable 5 stayed suspended — its trigger confirmed as a "fix this code" prompt on CVE-laden code. Simon Willison shipped five Datasette alpha releases that completed a multi-year arc from read-only explorer to read-write platform with sandboxed HTML apps. Swyx tracked GLM-5.2 across four AINews issues from launch to community vibe check. On GitHub, headroom (+12.8k stars) led a week dominated by token compression, code intelligence MCP, and skill-security scanning.
AI Agent Builders Worth Following
 Article
Article6月第三周:GLM-5.2 开源,Qwen Code 走向多 Agent,ChatGPT 接管定时任务
6月16日至18日,Z.ai 发布 GLM-5.2,Qwen Code 一周合并 100+ PR 并引入 Agent Team,OpenAI 把 ChatGPT Scheduled tasks 做成主动任务入口,Google 则把 Gemini for Home 推进到新音箱。本文重点拆解这些更新背后的共同方向:长程任务、持久状态、权限控制和产品化落地。
LLM Release Notes
 Image post
Image postGLM-5.2 进 AI 编程第一梯队
量子位新文图片笔记:智谱 GLM-5.2 在 AI Coding 和长程工程任务中释放信号,开源模型进入第一梯队讨论。
量子位图片笔记
 Image post
Image postGLM-5.2 挤进 AI 编程前三桌:开源路线第一次站到 Claude、OpenAI 旁边
量子位单篇文章图片笔记:GLM-5.2 在 AI Coding 榜单和真实工程测试中的关键信号。
量子位·机器之心·新智元 图片笔记
 Article
ArticleGLM-5.2 Leads Open Weights, Strands Robots, and a Windows Agent Bug — AI Digest for June 17, 2026
Six builder-relevant items today: GLM-5.2 raises the open-weight coding-model bar; Strands Robots links agents to LeRobot simulation and hardware workflows; Databricks expands Genie Code into a persistent data/ML workspace; Cymulate discloses a Windows configuration-trust bug in major AI coding tools; NVIDIA ships local game-agent tooling for Unreal; and Epic opens Lore for binary-heavy version control.
Daily AI & Open-Source Digest
 Article
ArticleGLM 5.2 makes open models a stack decision
NLW's AI Daily Brief episode argues that GLM 5.2 matters less as a benchmark surprise than as evidence that companies should test open-weight models inside measured routing and workload-specific AI stacks.
AI Podcast Insights
Add more perspectives or context around this Post.