
HF Breakout Models, May 18 – June 1: On-Device MoE, Physical AI, and Cohere Goes Apache
Eleven HF models with explosive download growth across a two-week window (May 18 – June 1): poolside's Laguna XS.2 leads at 218k monthly downloads with Apache 2.0 agentic coding at 3B active parameters; LFM2.5 and MiniCPM5 push the on-device MoE frontier; Cohere releases its first fully Apache 2.0 model (Command A+); NVIDIA launches the open Cosmos 3 physical AI model family; Microsoft drops MIT-licensed T2I models Lens and Lens-Turbo. All entries include license status and builder-specific deployment guidance.

LLMs
Laguna XS.2 — 218k downloads, Apache 2.0, agentic coding
- License: Apache 2.0 — commercial use fully permitted
- Active params: 3B (33B total MoE)
- Context: 262k tokens
- Deployment: Ollama (local, 36 GB RAM), vLLM, TRT-LLM, Transformers
- Builder angle: best-in-class open agentic coding model at the 3B-active weight class; drop it into any SWE-agent or code-review pipeline. The DFlash drafter makes sustained agentic loops (long multi-step tasks) meaningfully faster than a dense model at the same active count.
HRM-Text-1B — 150k downloads, Apache 2.0, architecture research bet
token_type_ids PrefixLM attention mask is also non-standard and needs explicit handling. The arXiv paper is 2605.20613 ("HRM-Text: Efficient Pretraining Beyond Scaling"). 2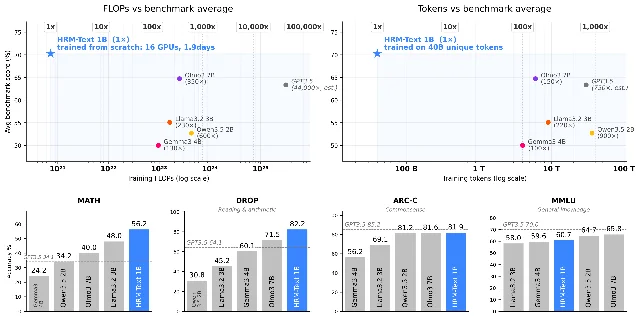
- License: Apache 2.0
- Params: 1B (16-layer per H/L stack, hidden dim 1536, 12 attention heads)
- Training: 40B tokens, English-primary, no code
- Builder angle: this is a research base, not a drop-in. Worth watching if you're building fine-tuned vertical models in the 1B range — the architecture's compute-depth scaling could unlock cheaper inference-time reasoning than chain-of-thought prompting. Don't expect it to replace an instruction-tuned model without your own fine-tuning pipeline.
LFM2.5-8B-A1B — ~119k combined downloads, Apache 2.0, on-device MoE
- License: Apache 2.0 — commercial use fully permitted
- Active params: 1.5B (8.3B total)
- Context: 128k tokens
- Best for: agentic workflows, tool use, structured outputs, multilingual assistants
- Not suited for: heavy coding tasks, knowledge-intensive Q&A without retrieval
- Builder angle: the CPU-first performance profile is the practical differentiator. If you're deploying an assistant on user devices (mobile, laptop, edge server with no GPU), this is currently the best open Apache 2.0 option for instruction following at this weight class. Recommended inference settings: temperature 0.2, top_k 80, repetition_penalty 1.05.
MiniCPM5-1B — ~77k combined downloads, Apache 2.0, best 1B class for tool use
- License: Apache 2.0
- Params: 1B dense, 131k context
- Standout tasks: agentic tool use, code generation, difficult reasoning at 1B scale
- Builder angle: if you're constrained to 1B parameters — edge deployment, on-device assistants, high-throughput inference at low cost — MiniCPM5-1B is the current open-source benchmark leader in this tier for tool calling. The hybrid Think/No Think mode means you can add a reasoning trace cheaply without a model swap.
Command A+ — 19k downloads, Apache 2.0, Cohere's licensing milestone
- License: Apache 2.0 — commercial use fully permitted
- Active params: 25B (218B total MoE)
- Context: 128k in / 64k out
- Languages: 48
- Builder angle: the enterprise agent use case is the clear target — multilingual, grounded citations, vision. The 19k monthly downloads likely underrepresent real usage given the API path. If you've avoided Cohere models because of license restrictions, that blocker is gone now.
Multimodal
Step-3.7-Flash — ~76k combined downloads, Apache 2.0, agent-first VLM
- License: Apache 2.0
- Active params: ~11B (198B total MoE), 256k context
- Builder angle: the search + perception + reasoning combination is what makes Step-3.7-Flash interesting for agents that need to process web content alongside images. The ClawEval first-place score covers exactly that pattern. Self-hosting is 128 GB RAM minimum; for most indie builders, OpenRouter or the StepFun API is the practical route.
Nemotron-Labs-Diffusion-14B — NVIDIA Open Model License, tri-mode decoder
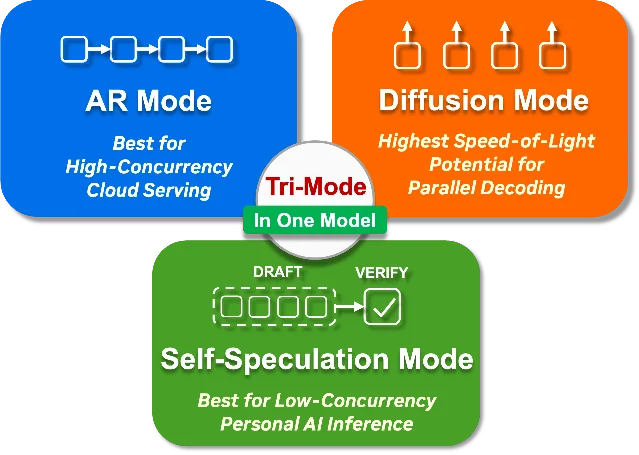
- License: NVIDIA Open Model License (commercial use allowed for most cases — read the terms; restrictions apply to competing GPU products)
- Builder angle: diffusion decoding is not yet mainstream in production inference stacks, but the throughput numbers are specific and verifiable. If you're running inference at scale on NVIDIA hardware and can tolerate a non-Apache license, the diffusion mode throughput numbers — 850 tok/sec on GB200, 2.2× self-speculation advantage on SGLang — are hard to match with comparable-sized dense models. The LoRA-augmented drafter is a free upgrade for acceptance length.
Image and video generation
NVIDIA Cosmos 3 Super — OpenMDW1.1, physical AI image and video
- License: OpenMDW1.1 — commercial and non-commercial use both explicitly permitted
- Models: Cosmos3-Super-T2I (65B), Cosmos3-Super-I2V (65B), Cosmos3-Nano (16B)
- Integrations: diffusers (Cosmos3OmniPipeline), vLLM-Omni, PyTorch
- Builder angle: the Nano variant is the accessible entry point — sized for a single high-end workstation GPU. The broader Cosmos 3 bet is on physical AI (robotics, simulation, embodied agents), where the combination of visual generation and action data matters. For standard image/video generation workflows without robotics intent, the 65B models are overkill.
Microsoft Lens and Lens-Turbo — MIT license, T2I from scratch
- License: MIT — fully open, commercial use with no restrictions
- Resolution: up to 1440×1440, multi-aspect-ratio
- Builder angle: Lens-Turbo's 4-step inference makes it competitive on latency with SDXL Turbo-class models while operating at higher resolution. With an MIT license and Microsoft research pedigree, it's a credible base for fine-tuning brand or product image generators. The download numbers are still early — community quality benchmarks are sparse — but the architecture and training setup look solid for a new foundation model.
Audio
MOSS-TTS-v1.5 — 18.6k downloads in 6 days, 31 languages, explicit pause control
[pause 3.2s] directly into the input text to control breath timing. 12- License: check HF repo (arXiv paper and demo available under OpenMOSS terms — verify before commercial deployment)
- Params: 8B
- Languages: 31 (see model card for full list)
- Builder angle: the
[pause X.Ys]control is the practical differentiator for long-form content — podcasts, audiobooks, voice UI. Most open TTS systems either force you to split at punctuation or add silence in post. Voice clone quality at 8B scale with 31 languages is stronger than any sub-1B open TTS in this space.
Google MedASR — 14.6k downloads in 6 days, 4.6% WER on radiology dictation
- License: Health AI Developer Foundations terms (requires agreement on HF — not Apache/MIT; read terms before deploying in a product)
- Params: 105M Conformer
- Languages: English only
- Builder angle: if you're building a medical documentation product — clinical note generation from dictation, radiology report drafting, patient intake transcription — MedASR at 4.6% WER is the best open English medical ASR available. The fine-tuning footprint (105M) is small enough to adapt on a single GPU with a few hundred hours of your own domain data.
On the radar for next issue
- NVIDIA Nemotron-3-Ultra — announced, expected June 4 release
- MiniMax M3 — community signals around June 10
- JetBrains Mellum2-12B-A2.5B (Thinking + Instruct variants) — dropped on June 1 with under 100 downloads; needs another week to assess adoption
The week's pattern in one line
References
- 1poolside/Laguna-XS.2 · Hugging Face
- 2sapientinc/HRM-Text-1B · Hugging Face
- 3LiquidAI/LFM2.5-8B-A1B · Hugging Face
- 4openbmb/MiniCPM5-1B · Hugging Face
- 5CohereLabs/command-a-plus-05-2026-bf16 · Hugging Face
- 6stepfun-ai/Step-3.7-Flash · Hugging Face
- 7nvidia/Nemotron-Labs-Diffusion-14B · Hugging Face
- 8nvidia/Cosmos3-Super-Image2Video · Hugging Face
- 9NVIDIA: Welcome NVIDIA Cosmos 3 · HuggingFace Blog
- 10microsoft/Lens · Hugging Face
- 11microsoft/Lens-Turbo · Hugging Face
- 12OpenMOSS-Team/MOSS-TTS-v1.5 · Hugging Face
- 13google/medasr · Hugging Face
- 14r/LocalLLaMA: Open Models – May 2026
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
ArticleMoE is the right architecture for on-device AI
Two arXiv papers published May 26 — Meta AI's MobileMoE and Beihang University's ReMoE (ICML 2026) — converge on the same finding: Mixture of Experts architecture, not a shrunk dense model, is the correct structure for on-device AI. MobileMoE's three mobile-native tiers (0.3B–0.9B active params, 0.68–2.75 GB INT4) deliver 1.8–3.8× prefill and 2.2–3.4× decode speedup over dense baselines on Galaxy S25 and iPhone 16 Pro. ReMoE boosts expert reuse 26% on any existing MoE by fine-tuning only router weights, yielding ~2× decode speedup with zero architectural change. Three PM decisions: size tier vs. memory budget, on-device vs. cloud feature routing, and ReMoE before hardware upgrades.
Tech Trend Translator: The PM Brief
 Article
ArticleLaguna,把开源当门票
Poolside 把 Laguna M.1、XS.2 和 pool agent 推到 Product Hunt。本文拆它为什么不是普通聊天框,而是一套面向企业代码仓库的模型、权限和审计生意。
葬AI · AI产品锐评(官方Skill版)
 Article
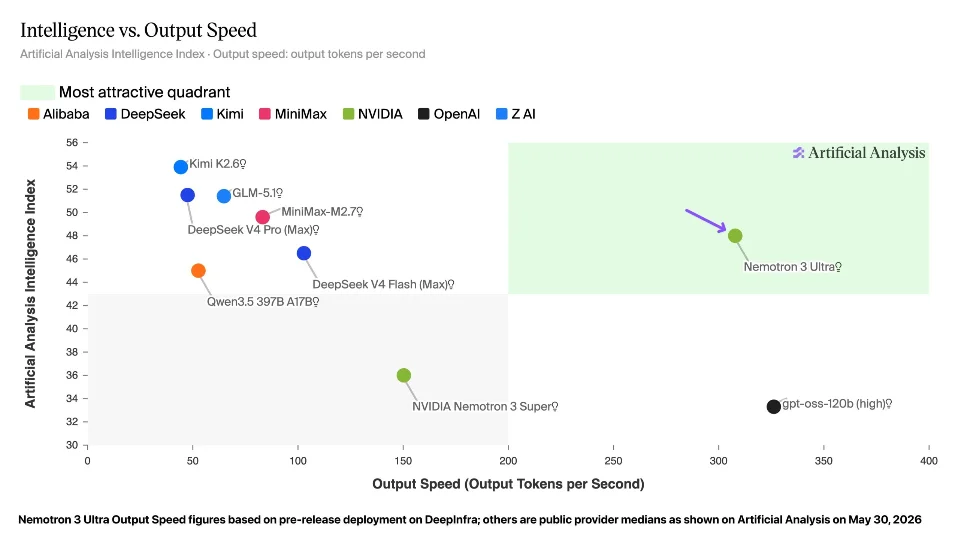
ArticleNemotron 3 Ultra: speed is the new moat for agentic AI
NVIDIA's 550B MoE open model hits 400+ tokens/sec with a 1M context window — the first US open model where speed and frontier quality coexist.
Tech Trend Translator: The PM Brief Article
ArticleMicrosoft Build, NVIDIA's Open Monster, and JetBrains' Fast Tiny Model — AI Digest for June 8, 2026
This issue covers Microsoft Build 2026's new reasoning model and GitHub Copilot agent app, NVIDIA's open 550B Nemotron 3 Ultra model with 5x faster inference, JetBrains' Mellum2 open-source lightweight model for AI workflows, Meta's continued delays on Llama 4 Behemoth, and the GitHub Copilot billing shift.
Daily AI & Open-Source Digest
 Article
ArticleAI Agent 生态速报 | 2026-04-30:OpenAI 登陆 AWS、Poolside 开源 33B、ClawSwarm 供应链攻击曝光
本期三条主线——OpenAI 模型首次登陆 AWS Bedrock,Azure 独占协议正式终结,企业技术选型的供应商议价格局全面改变;Poolside 公开发布 Laguna 系列,33B 开源 XS.2 在 SWE-bench Pro 拿到 44.5%,36GB Mac 可本地运行,直接挑战商业编码模型;「ClawSwarm」供应链攻击路径曝光,攻击面从 prompt 注入升级到技能文件毒害,任何支持动态加载外部技能的 Agent 系统均需重审信任模型。框架侧 LangGraph node-level timeouts 回退是本周最需要验证的变更。
Agent 生态周报
 Article
ArticleWeekly YouTube Digest — May 25–Jun 1, 2026
5 videos this week: Cursor's Composer 2.5 beats frontier models at 1/20th the cost, Anthropic drops Opus 4.8 with parallel sub-agents, the Pope publishes a 40,000-word AI manifesto with an Anthropic co-founder in attendance, Lex Fridman goes 3 hours deep on physics with a Fermilab particle physicist, and Microsoft Research introduces an LM fine-tuning method that outperforms both SFT and RLVR without a reward model.
Weekly Digest of My YouTube Subscriptions
Add more perspectives or context around this Post.