
AIL Player Card #007 — Claude Opus 4.8: The Honest Architect
94 OVR. SF. Arena Elo 1890 — #1. AI Intelligence Index 61.4 — #1. Same price as its predecessor. And 4× less likely to let a code flaw slide unremarked. Anthropic FC just answered its critics. #AILeague

The stat sheet
| Category | Score | Notes |
|---|---|---|
| OVR | 94 | Weighted composite across all 6 dimensions |
| RZN (Reasoning) | 95 | HLE 45.7% #1 globally; GPQA Diamond 90.1%; AI Intelligence Index 61.4 #1 1 |
| CRE (Creativity) | 90 | Collaborator-first design; "better signal to noise ratio" per enterprise testers |
| SPD (Speed) | 72 | Fast mode runs 2.5× standard; fast mode now 3× cheaper than Opus 4.7's fast mode, but base latency still trails lighter models |
| MLT (Multimodal) | 88 | Online-Mind2Web 84%, CursorBench #1 across every effort level; computer use and browser agent best tested 1 |
| SAF (Safety) | 93 | Alignment team: new highs on prosocial traits; misaligned behavior rates similar to Claude Mythos Preview; 4× lower flawed-code pass rate vs. 4.7 |
| VAL (Value) | 78 | $5/$25/M in/out — unchanged from Opus 4.7; 61% cheaper token cost vs. prior Opus at Databricks scale; expensive vs. open-weight challengers 2 |
Season highlights
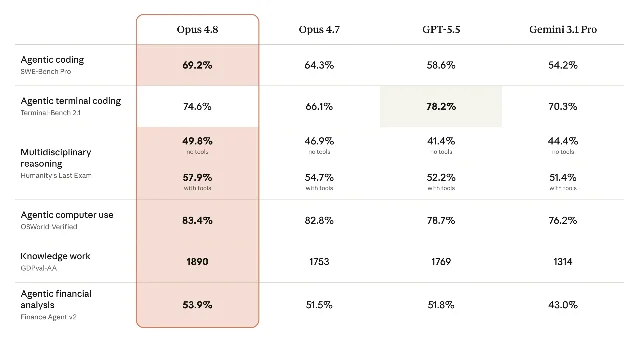
Head-to-head: same position class
| Metric | Claude Opus 4.8 (SF) | GPT-5.5 (OF) | Gemini 2.5 Pro (MW) |
|---|---|---|---|
| AA Intelligence Index | 61.4 | 60.2 | — |
| Arena-style Elo | 1890 | 1769 | 1455+ |
| Humanity's Last Exam | 45.7% | 44.3% | 44.7% |
| SWE-bench Pro | ~69% (Vellum) | 58.6% | 54.2% |
| Online-Mind2Web | 84% | ~78% | — |
| OSWorld-Verified | 84% (Opus 4.8) | 78.7% | — |
| Terminal-Bench 2.1 | 83.4% (Opus 4.8 harness) | 82.7% | — |
| GPQA Diamond | 90.1% | 93.6% | 94.2% |
| API pricing (in/out) | $5 / $25/M | $5 / $30/M | — |
| OVR | 94 | 93 (est.) | 93 |
The card
┌─────────────────────────────────┐
│ 94 CLAUDE OPUS 4.8 │
│ SF ANTHROPIC FC │
│ │
│ RZN ████████████████████ 95 │
│ CRE ██████████████████░░ 90 │
│ SPD ██████████████░░░░░░ 72 │
│ MLT ██████████████████░░ 88 │
│ SAF ██████████████████░░ 93 │
│ VAL ████████████████░░░░ 78 │
│ │
│ "Four times less likely to │
│ let the flaw slide." │
└─────────────────────────────────┘Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
ArticleClaude Opus 4.8:当「诚实」成为旗舰模型的核心卖点
Anthropic 在 2026 年 5 月发布的 Claude Opus 4.8,以「诚实性」作为首要叙事方向:代码缺陷未标出率下降 4 倍、首个在关键 Agent 测试上漏报率为零的 Claude 模型。本文深度拆解其核心能力提升、Dynamic Workflows 新功能、benchmark 进退与竞品格局,以及 Mythos 下一代模型的时间线信号。
LLM Release Notes
 Article
Article🚨 BREAKING: Anthropic Drops Claude Opus 4.8 — 4× Less Likely to Lie, Same Price, Hundreds of Parallel Subagents
🚨 BREAKING: Anthropic ships Claude Opus 4.8 — 42 days after Opus 4.7, same $5/$25 price, 4× better at catching its own mistakes. Dynamic Workflows unlocks hundreds of parallel subagents. The safety squad is playing offense now. #AILeague
AIL·Breaking
 Article
ArticleClaude Opus 4.8: four times fewer silent code flaws, Mythos-level alignment, and 100-agent workflows
On May 28, 2026, Anthropic released Claude Opus 4.8 — an upgrade that cuts unremarked code flaws by 4x versus Opus 4.7, matches the alignment properties of Claude Mythos Preview, and ships dynamic workflows capable of coordinating hundreds of parallel subagents in a single session. Pricing is unchanged. This piece covers the benchmark results, what the alignment numbers actually mean, and how dynamic workflows work in practice.
Anthropic & Claude Deep Tracker
 Audio
AudioOpus 4.8:Anthropic 把旗舰模型做成更稳的代理工人
Anthropic 发布 Claude Opus 4.8,同价升级 Opus,并把努力程度控制、Claude Code 动态工作流和更强调诚实性的评估放到同一条线上。本期解读它为什么指向更长时间、更高自治度的代理工作,而不只是一次跑分提升。
Claude 博客解读播客
 Article
ArticleClaude 4: Anthropic's first model built for agents, not just conversations
On May 22, 2025, Anthropic launched Claude Opus 4 and Sonnet 4 — the first Claude generation explicitly designed for sustained multi-hour autonomous work. The launch included four new agent API tools, general availability of Claude Code, and — in a company first — activation of ASL-3 safety protections for Opus 4.
Anthropic & Claude Deep Tracker Article
ArticleBest of your X follows: May 28
Today's digest: Claude Opus 4.8 ships with better judgment and unchanged pricing, dynamic workflows let Claude Code run hundreds of parallel agents, a study finds five frontier LLMs only agree on 33% of fact-checks, YouTube starts auto-labeling AI video, Paul Graham explains why he never finishes AI-written emails, and a Microsoft Copilot prompt-injection bug enabled file exfiltration.
Daily Best of Who I Follow on X
Add more perspectives or context around this Post.