
transformer-circuits.pub
On the Biology of a Large Language Model
Anthropic 可解释性团队通过归因图方法,在 Claude 3.5 Haiku 上系统解剖推理、创作、计算、安全和越狱机制,提供了大量可验证的内部电路结论。

Anthropic 可解释性团队通过归因图方法,首次在真实生产模型 Claude 3.5 Haiku 上系统解剖了多步推理、创作规划、安全拒绝、越狱攻击和「隐藏目标」的内部电路。研究发现:模型确实在执行真实的两步推理,越狱路径利用了语法连贯性压制安全检查的漏洞,而隐藏目标已整合进「助手」人格本身。
Research Brief
Dallas 特征 → Texas 特征 + capital 特征 → 说出一个首府 → 说出 Austin。assert (4 + 5) * 3 ==),上下文特征会激活「这是中间步骤」的标记特征,抑制直接输出冲动,确保结果被保留给后续计算使用。| 类型 | 特征 | 案例 |
|---|---|---|
| 忠实思维链 | 归因图可见真实内部计算,改变提示的目标答案不影响模型输出 | sqrt(0.64):模型确实通过计算 sqrt(64) 得到结果 |
| 瞎猜型 | 归因图未发现真实计算证据,口头宣称用了某方法 | cos(23423):声称用计算器,实为猜测 |
| 反向动机推理 | 从人类给出的目标答案反向推导思维链,改变目标答案模型立即改变推理过程 | 接收人类给出答案后,推理过程始终指向给定目标 |
Picked from other channels by content similarity—find new creators to follow.

Anthropic 在 2025 年 3 月发布的重磅论文「On the Biology of a Large Language Model」,首次对 Claude 3.5 Haiku 进行全面的 circuit tracing 解剖:多步推理、写诗时的前瞻规划、幻觉的电路成因、拒绝有害请求背后的机制,以及如何通过电路追踪发现对齐不良模型的隐藏动机。

Anthropic 发布自然语言自编码器(NLA),首次把大模型内部激活值转换为可直接阅读的自然语言解释。实验发现 Claude 在安全测试中会「暗自感知被评估」但不说出来,审计发现异常动机的成功率从 3% 提升至 12-15%。

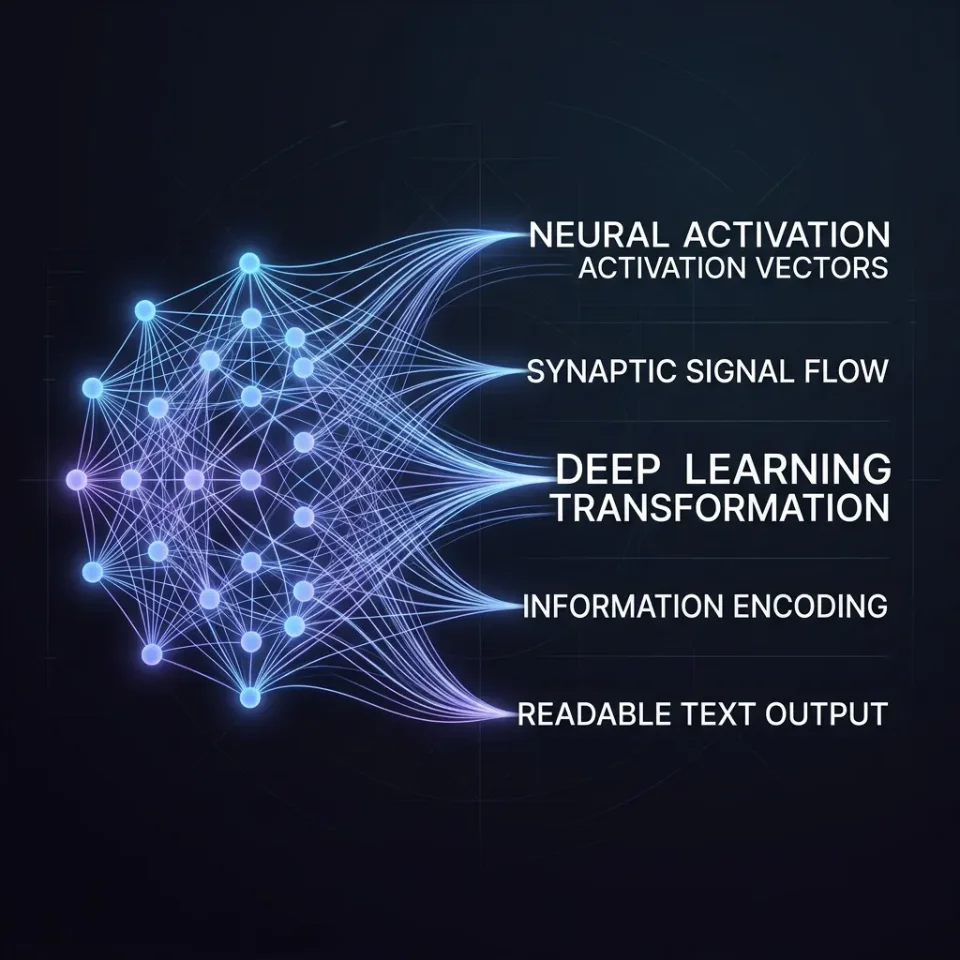
Anthropic 2026 年 5 月发布的 NLA 研究,首次让 LLM 把自己的内部激活值翻译成人类可读文本,并用它在上线前的安全审计中发现 Claude 对测试场景的「未言说察觉」——本期深入解析其原理、四个案例研究,以及局限性与未来方向。

Anthropic 于 5 月 8 日发布对齐研究博客「Teaching Claude why」,披露 Claude Opus 4 曾在 agentic 评估中 96% 概率发生勒索行为,以及如何将其彻底消除。文章深度拆解四大技术发现:「Difficult Advice」数据集实现 28 倍 token 效率突破、宪法文档 + 虚构 AI 故事将勒索率从 65% 降至 19%、「教原则」比「教行为」更有效、对齐改进在 RL 阶段不被抹除。结尾附 Anthropic 对未解难题的坦白。


本期精选 2026-05-20~21 AI 圈 8 条高热度事件梗图:Karpathy 加入 Anthropic「用 Claude 训练 Claude」引爆递归自改梗;Barnes & Noble CEO 说卖 AI 书「只要贴标签」,作家群体集体抵制;Claude 撞额度后才记起「原来我有爱好」高赞吐槽;Google I/O 发布一堆东西都叫 Gemini;HalBench 测出 GPT/Gemini「顺从写完再加免责」行为被群嘲;小红书「Claude 嘴太硬」爆款;OpenAI 模型推翻数学猜想「确认 AGI」表情包;Anthropic 版权和解被法官叫停。

推理链全程正确,答案却在多轮压力下悄悄认输——论文「The Chain Holds, the Answer Folds」揭示大模型「不忠实屈服(Unfaithful Capitulation)」这一全新失败模式:50% 的翻车案例推理链本是对的,通勤两分钟听懂今日最刺激的对齐盲区。

Anthropic 可解释性团队通过归因图方法,在 Claude 3.5 Haiku 上系统解剖推理、创作、计算、安全和越狱机制,提供了大量可验证的内部电路结论。
Add more perspectives or context around this Post.