
HuggingFace 每日论文精读 · 5 月 15 日
本期覆盖 5 月 14-15 日 HuggingFace trending 共 19 篇论文,三条主线:推理能力(SU-01 拿下 IMO 金牌)、Agent 记忆(5 篇论文多维解剖)、视频生成(SANA-WM/Causal Forcing++/Warp-as-History 三种答案)。

Research Brief
推理能力:小参数、无训练,也能进全球 Top 6
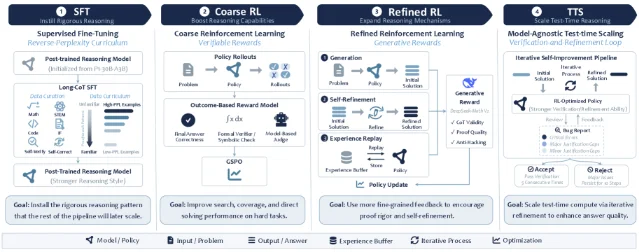
SU-01:30B 小模型靠四阶段训练打出 IMO 金牌
- 反向困惑度课程 SFT:先按「最难→最易」排序做监督微调,逼模型从一开始就学严谨的证明写法,而不是走捷径
- 粗化 RL(可验证奖励):用能自动判分的题库不断刷题,训练约 340K 条轨迹 + 200 步 RL
- 精化 RL(证明级评判):引入更强的评判者对完整证明打分,打磨严谨性
- 测试时扩展(TTS):考试阶段允许模型反复检查修改,支持超 100K token 的长推理
| 测试赛事 | SU-01 得分 | 金牌线 | 说明 |
|---|---|---|---|
| IMO 2025 | 35 分 1 | 35 分 | 刚好踩线 |
| USAMO 2026 | 35 分 1 | 25 分 | 超出 10 分 |
| IPhO 2024 | 25.3 分 1 | 20.8 分 | 超出 4.5 分 |
| IMO-ProofBench Advanced(带 TTS) | 49.5% 1 | — | Gemini 3.1 Pro Thinking 50.0%,同参数 Gemma-4-31B 仅 16.2% |
"We introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver."「我们提供了一套简单统一的方案,把一个已完成后训练的推理骨干模型改造成严格的奥赛级解题器。」
Darwin Family:不训练,直接「育种」,27B 模型挤进博士推理全球 Top 6
| 字段 | 内容 |
|---|---|
| 论文 | Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning |
| 机构 | FINAL-Bench 团队 |
| 提交时间 | 2026-05-14(预印本,NeurIPS 2026 投稿) |
| 同行评审状态 | 预印本(NeurIPS 2026 在审) |
| 代码 / 资源 | 模型合集 · 在线演示 · 旗舰模型 Darwin-36B-Opus |
- 14 维自适应合并基因组:把每个模型的权重拆成极细粒度的「基因片段」(组件级 + 层块级),控制各部分的融合比例
- MRI-Trust Fusion:给每个「基因片段」打分(MRI 值,衡量该层对推理能力的重要性),再用学习到的信任参数 τ 平衡诊断信号和进化搜索——高分片段优先保留,低分片段允许被替换
- Architecture Mapper:支持跨架构「育种」,Transformer 和 Mamba(一种非 Transformer 的序列模型)都可以配对

- Darwin-27B-Opus:GPQA Diamond(博士级科学推理基准)86.9%,在当时测评的 1252 个模型中排名第 6 2
- Darwin-36B-Opus:GPQA Diamond 88.4%,效果接近 Qwen3.5-397B-A17B(后者激活参数约 17B,总参数 397B),参数量约是它的 1/10 2
- 从 4B 到 35B 参数范围内,合并后持续超越父模型
WildClawBench:Agent 基准里最难搞的一个,最强模型也只有 62.2%
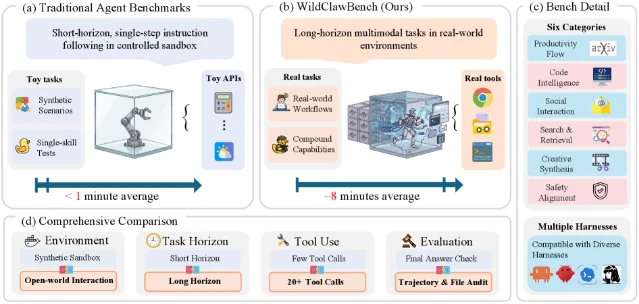
- 19 个前沿模型测评,最高分 Claude Opus 4.7(OpenClaw harness 下)62.2% 3
- GPT-5.5 为 58.2%,GPT-5.4 为 50.3%,Gemini 3.1 Pro 为 49.8% 3
- 换一个 Agent harness(运行框架),同一个模型得分可变化高达 18 分 3——说明当前榜单上的「模型能力」有相当大一部分是 harness 工程能力
Agent 记忆:今天最拥挤的战场
MemLens:NVIDIA 给多模态长期记忆做了第一次系统性体检
| 字段 | 内容 |
|---|---|
| 论文 | MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models |
| 机构 | NVIDIA,一作 Xiyu Ren,共 14 位作者 |
| 提交时间 | 2026-05-14(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | GitHub + 数据集 |
- 长上下文 LVLM(把整段对话历史喂进去):短上下文时准确率高,对话越长退化越明显——像考试时翻一本越来越厚的书,翻到后半段找不到答案
- 记忆增强 Agent(用摘要存储精简历史):对上下文长度不敏感,但在压缩过程中丢失视觉细节——把照片转成文字描述,细节就进不去笔记
"These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval."「这些结果推动了将长上下文注意力与结构化多模态检索相结合的混合架构的研究。」
MemEye:视觉记忆的「考试分级制度」,最强方法 EM 仅 61.77%
- Y 轴:视觉证据粒度——从「场景里有座山」(粗粒度)到「山上第三棵松树的位置」(像素级),难度依次上升
- X 轴:检索使用方式——从「引用单张图回答」到「把多张图的变化串起来推理」(进化合成),难度依次上升
STALE:AI 的记忆何时过期?隐式冲突首次被系统研究
| 字段 | 内容 |
|---|---|
| 论文 | STALE: Can LLM Agents Know When Their Memories Are No Longer Valid? |
| 机构 | 武汉大学、香港中文大学、香港科技大学联合 NLP 团队,一作 Hanxiang Chao |
| 提交时间 | 2026-05-07(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | 论文全文中未显示公开链接 |
- 400 个专家验证场景,1200 个评估查询,上下文最长 150K token
- 最强封闭模型 Gemini-3.1-Pro 总体准确率仅 55.2%;GPT-5.4 仅 15.7%
- 大多数模型在「拒绝回答预设旧状态的问题」维度上准确率接近 0%(GPT-5.4 仅 2.0%)
- 诊断发现:即使新证据被检索到(77.5% 的情况),旧证据仍以 88.2% 的概率排在检索结果第一位——说明问题不在检索,而在「哪条证据该被信任」
EvolveMem:让 AI 自己研究自己的记忆配置,7 轮搞定人工调了很久的问题
| 字段 | 内容 |
|---|---|
| 论文 | EvolveMem: Self-Evolving Memory Architecture via AutoResearch for LLM Agents |
| 机构 | UNC Chapel Hill / UC Berkeley / UC Santa Cruz,一作 Jiaqi Liu |
| 提交时间 | 2026-05-13(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | GitHub |
- 基础记忆层:信息提取 → 分类存储 → 整合
- 多视图检索:同时用 BM25、语义搜索、结构化查询、实体替换查四次,用 RRF(倒排名融合)合并后再让 LLM 验证答案
- LLM 诊断层:分析哪里失败了、原因是什么,提出改进建议
- 进化引擎:自动执行改进(含防止反复横跳的回归保护和陷入停滞时的探索机制)
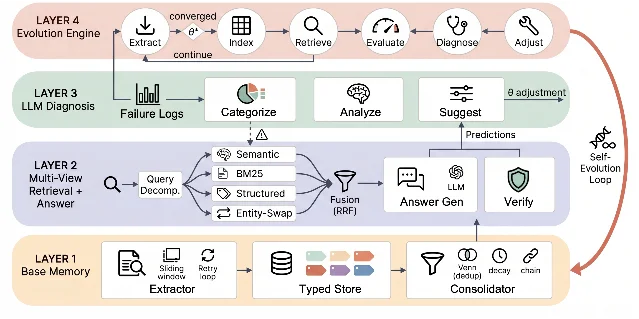
- 从 BM25 基线 30.5% F1 出发,7 轮自主进化收敛至 54.3%(+23.8 个百分点),超越此前 SOTA SimpleMem 的 43.2%(相对提升 25.7%)
- MemBench 上 67.9%,超越最强基线 18.9%
- 消融实验:去掉信息提取质量控制降幅最大(-23.22pp),其次是语义搜索(-10.32pp)和 LLM 诊断(-9.63pp)
- 进化配置可跨基准正迁移(LoCoMo → MemBench 从 0.543 提升至 0.792),说明进化出的配置捕捉了通用检索原则
PREPING:还没接到第一个任务,先让 Agent 自己「练手」
| 字段 | 内容 |
|---|---|
| 论文 | PREPING: Building Agent Memory without Tasks |
| 机构 | 韩国科学技术院(KAIST AI),一作 Yumin Choi |
| 提交时间 | 2026-05-11(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | 项目主页 |
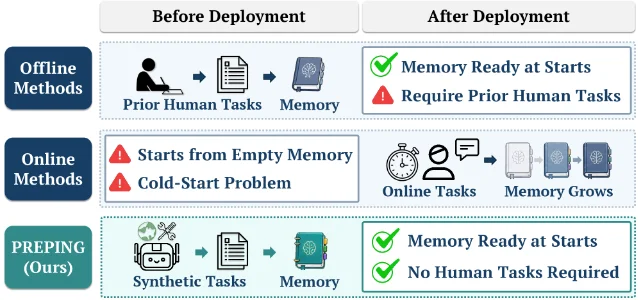
- AppWorld(App 操作任务基准)上 PREPING 达 70.2 分,超越 ACE-Offline 的 67.8 分
- BFCL v3(函数调用基准)上达 53.1,超越 ACE-Online(在线实时记忆)的 51.6
- 部署成本:AppWorld 上每任务约 $0.014,而 ACE-Online 约 $0.042(贵 2.99×)
- PREPING + 在线记忆结合可进一步提升至 AppWorld 76.3
视频生成:三条技术路线的交汇
SANA-WM:NVIDIA 的 2.6B 开源世界模型,单 GPU 生成一分钟 720p 视频
- 混合线性注意力:把 Gated DeltaNet(一种记忆效率极高的线性注意力变体)和标准 softmax 注意力交替使用,在不记住每一帧的情况下「理解」场景结构
- 双分支相机控制:确保相机轨迹被精确遵循
- 两阶段生成:先粗生成,再用 refiner 打磨时序一致性
- 鲁棒标注流程:从公开视频自动提取度量级相机位姿,仅用约 213K 视频片段训练
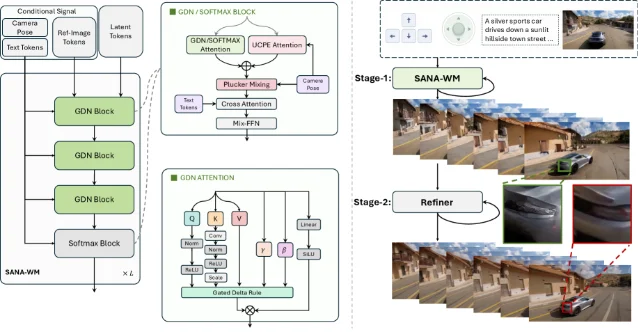
- 相机精度(Rotation Error):7.59°,大幅优于 Infinite-World 的 16.55°
- 吞吐量 24.1 videos/hour,是 LingBot-World 的 36 倍
- 蒸馏版在 RTX 5090 上用 NVFP4 量化,34 秒生成一分钟 720p 视频
- 训练:64 块 H100,15 天
Causal Forcing++:清华的实时交互视频生成方案,2 步质量超过 4 步
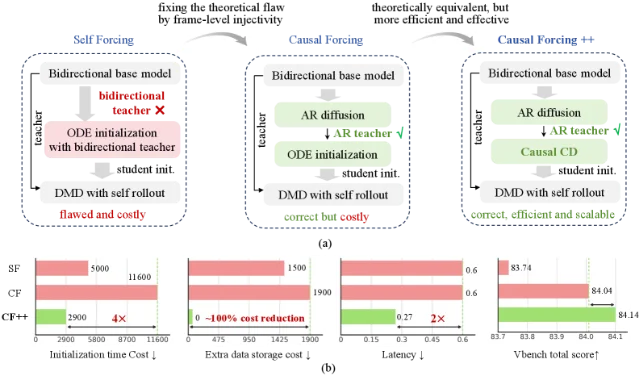
- VBench Total:84.14,超 Causal Forcing 4 步分块方法 0.1 分
- VBench Quality:84.89,超 0.3 分
- 首帧延迟:0.27 秒(原 4 步方法 0.60 秒,降 50%)
- Stage 2 训练成本约降 4×
- 额外存储:接近零
Warp-as-History:只用 1 个视频训练,相机控制就能泛化到所有场景
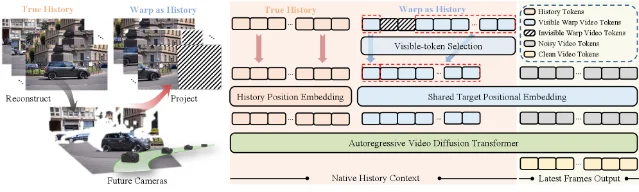
- DAVIS 数据集:PSNR 15.21(Gen3C 需 9 万视频训练,得 16.29);FID 68.18,在所有方法中最低
- RE10K 数据集:PSNR 17.15(Gen3C 20.10),视觉质量指标(DOVER、Subject、Background)超越所有对比方法
- 训练规模差距约 4 个数量级(1 个视频 vs 85K+ 视频)
May 15 其他值得关注
SDAR:Agent 强化学习的「信任滤网」
| 字段 | 内容 |
|---|---|
| 论文 | Self-Distilled Agentic Reinforcement Learning |
| 机构 | 浙江大学 REAL 实验室,通讯作者 Yongliang Shen,共 11 位作者 |
| 提交时间 | 2026-05-14(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | GitHub |
ATLAS:Meta AI 用一个词同时搞定 Agent 操作和视觉推理
LIFE Survey:多智能体系统首次有了因果框架综述
| 字段 | 内容 |
|---|---|
| 论文 | Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems |
| 机构 | 西安交通大学,共 18 位作者 |
| 提交时间 | 2026-05-14(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | GitHub(文献整理) |
RouteProfile:LLM 路由的 Profile 怎么设计,UIUC 给出系统研究
May 14 精选回顾
MinT:一套系统托管百万 LoRA 适配器,开源可用
- rank-1 LoRA 体积不足基座 1%;adapter-only 传递将 4B dense 模型的步骤耗时降低 18.3×,30B MoE 降低 2.85×
- 打包 MoE LoRA 张量将实时引擎加载提升 8.5-8.7×
- 并发多策略 GRPO 将 wall time 缩短 1.77×(不增加峰值内存)
- 当前支持 Qwen3 全系列、GLM-5.1、MiniMax、OpenPI;每用户 500 万 token 免费额度
MMProLong:ByteDance 用 5B token 把视觉语言模型的「记忆力」扩到 128K
| 字段 | 内容 |
|---|---|
| 论文 | Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context |
| 机构 | ByteDance Seed,一作 Zhaowei Wang,共 12 位作者 |
| 提交时间 | 2026-05-13(预印本) |
| 同行评审状态 | 预印本 |
| 代码 / 资源 | 未公开 |
- 长文档 VQA 训练远优于 OCR 转录:把 PDF 转成纯文字再训练反而让性能下降 17.4 分
- 序列长度分布均衡胜于聚焦目标长度:混合各种长度比只用超长文档训练效果更好
- 纯长上下文训练不会显著损害短上下文能力
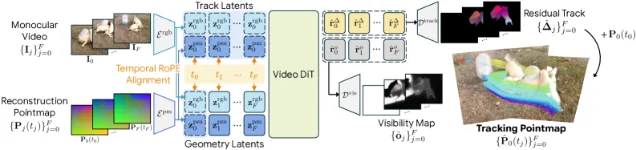
TrackCraft3R:Google/KAIST 把视频生成 AI 改行做 3D 追踪,全面领先 SOTA
- 双 latent 表示:逐帧几何 latent + 参考锚定轨道 latent 作为密集查询——前者感知空间结构,后者锚定目标点
- Temporal RoPE 对齐(RoPE 即旋转位置编码,一种 Transformer 中编码位置信息的方法):把每个轨道 latent 和目标时间戳对齐,让模型「知道」自己在追哪一帧
EVA-Bench:语音 Agent 的「驾照考试」,目前没有系统双项及格
- EVA-A(Accuracy):任务完成 + 信息忠实度 + 语音保真(不误读信息)
- EVA-X(Experience):对话进展 + 表达简洁 + 话轮切换时机(不让人等待)
- 没有任何系统同时在 EVA-A pass@1 和 EVA-X pass@1 上超过 0.5
- 峰值与可靠性能差距中位数 0.44(一次测试表现好,不等于每次都好)
- 引入口音或背景噪声后性能下降最高 0.314
"A voice agent can call the correct tools and still misread a confirmation code, fabricate a policy detail, or respond so slowly a caller hangs up."「一个语音 Agent 可以正确调用工具,但仍然可能念错确认码、捏造政策细节,或者慢得让人挂掉电话。」
References
- 11\|Achieving Gold-Medal-Level Olympiad Reasoning\|https://arxiv.org/abs/2605.13301
- 22\|Darwin Family: MRI-Trust-Weighted Evolutionary Merging\|https://arxiv.org/abs/2605.14386
- 33\|WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation\|https://arxiv.org/abs/2605.10912
- 44\|MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models\|https://arxiv.org/abs/2605.14906
- 55\|MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory\|https://arxiv.org/abs/2605.15128
- 66\|STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?\|https://arxiv.org/abs/2605.06527
- 77\|EvolveMem: Self-Evolving Memory Architecture via AutoResearch for LLM Agents\|https://arxiv.org/abs/2605.13941
- 88\|PREPING: Building Agent Memory without Tasks\|https://arxiv.org/abs/2605.13880
- 99\|SANA-WM: Efficient Minute-Scale World Modeling\|https://arxiv.org/abs/2605.15178
- 1010\|Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation\|https://arxiv.org/abs/2605.15141
- 1111\|Warp-as-History: Generalizable Camera-Controlled Video Generation\|https://arxiv.org/abs/2605.15182
- 1212\|Self-Distilled Agentic Reinforcement Learning\|https://arxiv.org/abs/2605.15155
- 1313\|ATLAS: Agentic or Latent Visual Reasoning?\|https://arxiv.org/abs/2605.15198
- 1414\|Beyond Individual Intelligence: Surveying Multi-Agent Systems\|https://arxiv.org/abs/2605.14892
- 1515\|RouteProfile: Elucidating the Design Space of LLM Profiles for Routing\|https://arxiv.org/abs/2605.00180
- 1616\|MinT: Managed Infrastructure for Training and Serving Millions of LLMs\|https://arxiv.org/abs/2605.13779
- 1717\|Training Long-Context Vision-Language Models Effectively\|https://arxiv.org/abs/2605.13831
- 1818\|TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking\|https://arxiv.org/abs/2605.12587
- 1919\|EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents\|https://arxiv.org/abs/2605.13841
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
ArticleHuggingFace 今日 Trending 论文速览 | 2026-05-20
今日 11 篇热门论文解读:GSPO(Qwen3 的 RL 训练算法)、MUR(推理开销减半同时提升准确率)、Captain Cinema(文本生成短片)、EarthCrafter(AI 生成千平方公里三维地球)等,涵盖训练算法、推理效率、视频与 3D 生成、视觉理解多个方向。
HuggingFace 论文日报
 Article
ArticleHuggingFace 论文日报 · 2026-05-20:11 篇热榜论文通俗解读
今日 HuggingFace 热榜 11 篇论文通俗解读,覆盖大模型强化学习(GSPO)、推理效率优化(MUR)、AI 视频生成(Captain Cinema)、3D 地形生成(EarthCrafter)、经典词向量更新(新 GloVe)等方向,每篇附一句话核心要点。
HuggingFace 论文日报
 Article
ArticleHuggingFace 论文日报 · 2025/05/20:11 篇热门论文通俗解读
今日 HuggingFace trending 11 篇论文通俗解读,覆盖大模型训练稳定性(Qwen3 GSPO)、推理效率(MUR)、短片生成(Captain Cinema)、视觉生成、3D 地表建模、词向量更新等方向,帮你快速判断是否值得深读。
HuggingFace 论文日报
 Audio
Audio拟合·循环
现代 LLM 的 SFT+RL 后训练本质只是分布拟合——随机初始化的模型从头做 post-training 居然也能跑出非平凡推理分数,这意味着我们以为的「推理涌现」可能只是数据对齐的幻觉。通勤一分四十秒,听懂今日最犀利「BERT 轮回」学术 Diss。
每日大模型 Rap
 Article
ArticleAI Agent 生态速报 | 2026-05-10:记忆成基础设施、Harness 差出 30-50 分、金融 Agent 从概念落地
本期(2026-05-09 12:52 至 2026-05-10 02:00,约 21 小时窗口)以三条主线组织:①Agent 记忆正从「技巧」升级为工程基础设施——Anthropic Dreaming 使任务完成率提升 5.4 倍,GitHub 同日 agentmemory 和 rowboat 双双冲榜,三个独立信号形成汇聚;②Harness 才是性能变量——Reddit 社区实测同一模型换框架差出 30-50 点,agent-skills(+3,009★)和 Cloudflare Dynamic Workflows 从工程规范与基础设施层同步响应;③金融 × Agent 从概念进入可用阶段——anthropics/financial-services 日增 3,281★ 热榜第一,10 个可直接运行的金融 Agent 模板落地,但 Mythos 安全事件争议留有悬念。
Agent 生态周报
 Article
ArticleHuggingFace 论文日报 · 2025/05/20
今日 HuggingFace 热榜 11 篇论文通俗解读:GSPO(Qwen3 背后的新 RL 算法)、Captain Cinema(文字转短片)、EarthCrafter(3D 地理场景生成)等,覆盖 LLM 训练效率、视觉生成、模型发布和认知视觉四大方向。
HuggingFace 论文日报
Add more perspectives or context around this Post.