
June 24, 2026 · 8:10 AM
AI 模型省钱的秘密,藏在少看几眼
MIT Technology Review 的 Will Douglas Heaven 写到,Subquadratic 声称用稀疏注意力让大模型更快、更便宜、更省电。读完这篇,你会理解为什么这可能是一次真正的效率突破,也可能只是还没被真实用户检验的漂亮基准。

Research Brief
导读
MIT Technology Review 的 Will Douglas Heaven 这篇文章写的不是又一个新模型发布,而是一个更硬的问题:如果大型语言模型(LLM,即大语言模型)的主要成本来自「每个词都要看每个词」,有没有办法让它只看真正相关的连接?Subquadratic 声称自己的 SubQ 做到了;文章最值得读的地方,是它一边解释这个主张为什么诱人,一边把怀疑保留下来。1
原文信息:Will Douglas Heaven,MIT Technology Review,2026 年 6 月 19 日。原文题为 A startup claims it broke through a bottleneck that’s holding back LLMs。1

全文总结
文章从一个很容易被过度包装的发布讲起。迈阿密 AI 初创公司 Subquadratic 上个月从隐身状态公开亮相,声称解决了困扰大型语言模型近十年的数学瓶颈。它说自己的新模型 SubQ 比市场上其他模型更快、更便宜、能耗更低,还能一次处理多达通常模型 12 倍的文本。这样的说法太大,最初又只拿出少量自家测试分数,所以外界反应很自然:要么这是 Transformer 以来最大的突破,要么就是「AI 版 Theranos」。1
一个月后,Subquadratic 开始补证据。它公开了模型卡,并让第三方评测公司 Appen 跑了更多测试。公司联合创始人兼 CTO Alex Whedon 承认,如果一开始就把第三方基准一并发布,很多怀疑本可以提前化解。Appen 生成式 AI 研究负责人 Jeanine Sinanan-Singh 的态度也很微妙:结果让她兴奋,因为它似乎验证了 SubQ 的架构;但如果一个「震撼」结果只由公司自己宣布,就没有那么可信。1
文章随后把技术问题讲清楚。今天主流 LLM 的核心机制是 Transformer(2017 年 Google 研究者在论文 Attention Is All You Need 中提出的架构),里面最关键的步骤叫 dense attention,中文可理解为「密集注意力」。模型处理一段文本时,会先把每个词或词的一部分编码成数字,再把这些数字两两相乘,捕捉词与词之间的关系。10,000 个词会触发将近 5,000 万次乘法;文本长度翻倍,计算量大约会变成四倍。这个「二次方扩张」就是成本、速度和耗电问题的根源。1
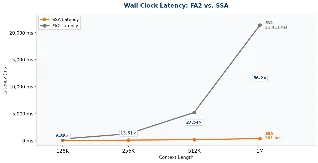
Loading chart…
这张图只画了原文里的小例子,没有画 10,000 个词对应的近 5,000 万次乘法。原因很简单:数量级一拉开,小例子会被压成一条贴地线。它要说明的是同一个机制,文本越长,模型要检查的词间关系不是线性增加,而是迅速爆开。1
Subquadratic 的方案是放弃 dense attention,改用 sparse attention,也就是「稀疏注意力」。思路并不神秘:不是所有词与词的关系都重要,因此模型不必把每个数字都拿去和其他所有数字相乘。Whedon 用读书来解释这件事:读一本书时,没有人会同时盯着第一个词和第二个词、第一个词和第三个词一路比下去。真正难的是,模型必须知道哪些关系可以跳过,哪些关系不能跳过。1
这也是文章没有把 SubQ 写成确定性胜利的原因。稀疏注意力不是新想法,许多人都试过。前 OpenAI 研究员 Will Depue 说,几乎所有能想到的办法都有人试过;这不是不可能,但像跑进四分钟一英里一样难。过去的问题在于,固定模式的选择常常不够聪明,比如总是比较第一个词和第五个词。Subquadratic 说自己的独特之处,是动态决定每段文本里哪些词该被关注。但它没有公开具体选择机制,只说「秘密酱汁」就在这里。1
测试结果看起来确实抓人。Appen 在一个纯速度测试中发现,SubQ 比使用 FlashAttention 的模型快 56 倍;在 LiveCodeBench(用真实竞赛题测试模型写代码能力的基准)上,SubQ 得到 89.7%,被 Appen 认为仍有前沿级代码能力。成本数字更夸张:Subquadratic CEO Justin Dangel 说,Anthropic 的 Opus 4.6 跑 Nvidia(英伟达,芯片和 AI 基准工具公司)开发的 RULER 128 测试需要 2,600 美元,而 SubQ 只花 8 美元。这个成本说法仍难以独立验证,因为 SubQ 尚未大规模开放。1
长上下文能力是另一个亮点。SubQ 的上下文窗口最高可达 1,200 万 token;多数顶级模型目前约为 100 万 token。Whedon 向作者演示时,让 SubQ 处理一个需要在 400 份文档中推理的任务,SubQ 几秒内给出结果;同样任务交给 Perplexity(AI 搜索引擎)时,后者没能载入全部 400 份文档。Appen 还做了 Needle-in-a-Haystack(大海捞针测试,用来测试模型能否在大规模文本里找回特定信息),报告称 SubQ 在 600 万和 1,200 万 token 窗口下得分 98%。1
但文章最后把读者拉回地面。基准测试只能说明模型在特定条件下表现如何,不能替代真实用户把它放到各种任务里折腾。SubQ 目前定位在写代码和搜索超大数据集,已有数万潜在用户申请早期访问,其中包括 500 多个企业客户,但真正拿到访问权的人很少。Subquadratic 解释说,自己还是小公司,资源有限,无法一下子服务太多人。1
最扎实的怀疑来自模型来源。SubQ 并不是从零训练出来的,它复用了中国开源模型 Qwen 的一版权重作为起点。借用已有模型权重是常见做法,但这削弱了它「彻底重造 LLM」的说法。Depue 给出的结论也因此很克制:Subquadratic 可能做出了真实且有用的东西,但公开证据还不足以支持「已经解决二次注意力瓶颈」这个更强的主张。1
关键细节
- Subquadratic 声称 SubQ 能一次处理最多 1,200 万 token,是多数顶级模型约 100 万 token 上下文窗口的 12 倍。这个数字如果成立,意义不在「能塞更多字」本身,而在模型可以直接处理成百上千份文档,少依赖外部检索和分段拼接。1
- Appen 的速度测试显示,SubQ 比使用 FlashAttention 的模型快 56 倍;LiveCodeBench 得分为 89.7%。速度快如果伴随能力掉得很厉害,就只是工程取舍;文章里的争议点恰恰是,SubQ 声称自己没有明显牺牲代码能力。1
- Dangel 给出的成本对比非常惊人:Anthropic Opus 4.6 跑 RULER 128 要 2,600 美元,SubQ 只要 8 美元。但原文也提醒,这个成本说法目前较难验证,因为 SubQ 还没有广泛开放。1
- SubQ 在 Needle-in-a-Haystack 测试中,据 Appen 报告,在 600 万和 1,200 万 token 窗口下都达到 98%。这个测试考的是从海量文本里找回特定信息,适合展示长上下文检索能力,但仍不能证明模型在所有复杂任务上都可靠。1
- SubQ 复用了 Qwen 的模型权重,而不是从零训练。这个事实让它的商业价值和科学主张分开了:它可能是一套有用的新架构,也可能只是还没证明自己足以替代 Transformer 的高效改造。1
金句
「SubQ is either the biggest breakthrough since the Transformer ... or it’s AI Theranos.」1这句话来自 AI 工程师 Dan McAteer 对外界反应的概括。它好在不站队:真正的突破和漂亮的幻觉,在早期往往长得很像。
「If you’re reading a book, you’re not going to look at the first and second words, first and third—that’s insane.」1Whedon 用这句话解释稀疏注意力的直觉:语言理解不需要检查所有词对所有词的关系,关键是别跳过真正有意义的关系。
「They may have built something real and useful. But the public evidence does not yet justify the stronger claim that they have solved the quadratic attention bottleneck.」1Depue 的这句判断最像全文的底线:先承认可能有用,再拒绝把「有用」直接升级成「革命」。这也是读这篇文章最该带走的分寸感。


Add more perspectives or context around this Post.