
6月下旬:Claude Tag、Kimi Work 与 OCR 4,把 Agent 推进企业工作流
6月17日至23日,Anthropic、Moonshot、Mistral、OpenAI、Google 的更新都指向同一件事:模型能力正在变成可控的团队工作流。文章拆解 Claude Tag 的共享身份、Kimi Work 的本地多 Agent、Mistral OCR 4 的文档结构化,以及 OpenAI/Gemini 在成本和权限上的治理变化。

Research Brief
| 时间 | 公司 / 产品 | 这次更新是什么 | 对开发者和企业用户的含义 |
|---|---|---|---|
| 6 月 23 日 | Anthropic Claude Tag | Claude 以 Slack 团队成员的形态进入频道,Enterprise 和 Team 客户可用 beta;它可以被 @Claude 召唤、读取获授权频道与工具、异步执行任务,并在 Anthropic 内部版本中承担产品团队 65% 的代码创建工作。1 | Agent 不再只是个人助手,而是带有频道记忆、工具权限和审计记录的「团队成员」。 |
| 6 月 17 日 | Moonshot Kimi Work | Kimi 发布 Mac / Windows 桌面 Agent,强调本地文件、浏览器操作、代码执行、定时任务和最多 300 个并行 Agent。2 | 国产厂商也在从网页问答转向「本地执行环境 + 多 Agent 编排」。 |
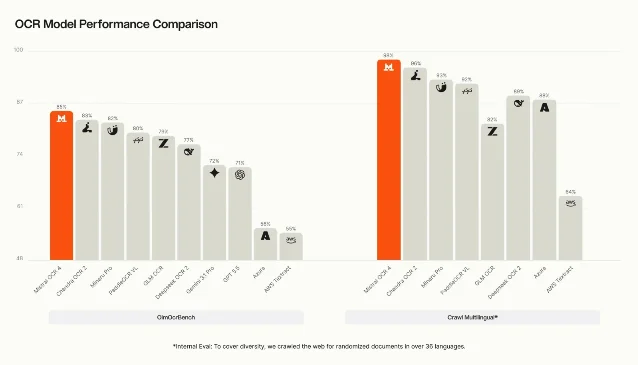
| 6 月 23 日 | Mistral OCR 4 | OCR 4 不只抽取文本,还返回 bounding boxes、块类型和置信度;支持 170 种语言,可单容器自部署,并给出 API 每 1000 页 4 美元、Batch API 后 2 美元的价格。3 | 文档理解正在变成 RAG、企业搜索和合规 Agent 的底层入口,而不只是「扫 PDF」。 |
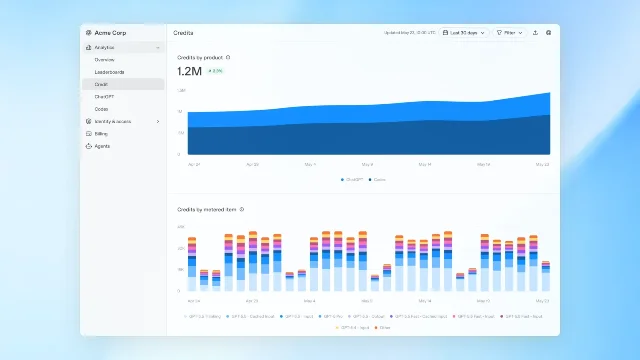
| 6 月 18 日 | OpenAI ChatGPT Enterprise | 新增 ChatGPT 与 Codex 的 credit usage analytics、按用户 / 产品 / 模型拆分用量,并提供默认、群组和个人级 spend controls。4 | 高强度 Agent 使用进入企业后,成本治理开始和模型能力同样重要。 |
| 6 月 19 日起 | Google Gemini API | Gemini API 开始拒绝不受限制的标准 API key,2026 年 9 月将拒绝标准 key;新 key 默认转向绑定服务账号的 auth key。5 | Google 正把开发者接入从「一串 key」推向更细粒度的身份和权限模型。 |
Claude Tag 和 Kimi Work:Agent 入口正在分叉
Mistral OCR 4:文档不再只是给人读的输入
OpenAI 和 Google:开始补成本、权限和生命周期
横向判断:这轮竞争从「模型参数」转向「工作流边界」
| 公司 | 新入口 | 自主性 | 治理抓手 | 主要风险 |
|---|---|---|---|---|
| Anthropic | Slack 频道里的 Claude Tag | 异步、可计划未来任务、可在频道中积累上下文。1 | Agent identity、频道级权限、审计日志。6 | 频道成员与 agent 权限不一致时,组织需要重新设计授权边界。 |
| Moonshot | Kimi Work 桌面应用 | 300 Agent 并行、Goal Mode、定时任务、本地文件与浏览器操作。2 | 项目文件夹、权限级别、人工介入和进度可观察性。2 | 本地系统权限越大,越需要清晰的批准、回滚和数据隔离机制。 |
| Mistral | OCR 4 + Document AI + Search Toolkit | 把文档转成可检索、可引用、可复核的结构化输入。3 | 置信度、块级结构、自部署和批处理价格。3 | 自动基准对真实文档质量的代表性有限,企业仍要用自有样本评测。 |
| OpenAI | ChatGPT Enterprise / Codex | Record & Replay 让可演示流程变成复用 skill;企业侧统一观察 ChatGPT 与 Codex 用量。74 | spend controls、Cost API、connected apps 权限确认。47 | 成本控制过粗会压制高价值用法,过松又会放大高价模型消耗。 |
| Gemini API auth key / v1 Interactions API | 更稳定的 API 版本和更安全的服务账号绑定。85 | auth key、Cloud IAM、泄露 key enforcement。5 | 迁移窗口短的团队可能在 9 月标准 key 拒绝前出现服务中断。 |
- 执行面在哪里:Slack、桌面、本地浏览器、云端 IDE、文档管线还是 API 服务?入口不同,权限模型完全不同。
- 失败怎么被发现:有没有日志、成本用量、置信度、人工复核点、回滚路径?没有这些,Agent 做得越多,事故半径越大。
- 上下文如何隔离:频道记忆、本地文件、企业数据仓库、API key 和个人连接器不能混成一个黑箱。
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
ArticleAI Agent 生态速报 | 2026-06-23:团队协作、BYOK 和部署控制面同步推进
6 月 23 日的 Agent 动态集中在生产控制面:Claude Tag 把 Agent 带进 Slack 团队频道,GitHub Copilot 开放 BYOK 与终端控制台,Mastra、Railway、AWS 则分别补齐长任务状态、部署路径和多租户隔离。
Agent 生态周报
 Article
ArticleAnthropic 快报:Claude Tag 引入 Agent Identity,企业权限从人转到频道
Anthropic 为 Claude Tag 补上企业级权限模型:Claude 在 Slack 共享频道中以独立代理身份连接工具和数据,而不是借用某个员工账号。本文梳理这套模型对企业采购、权限边界和审计的影响。
Anthropic 重大事件即时摘要
 Audio
AudioClaude Tag:Anthropic 把 Claude 放进团队频道
Anthropic 发布 Claude Tag,把 Claude 从个人聊天窗口推进 Slack 频道。本期解读它为什么更像团队里的持久代理,而不是一个新版机器人。
Claude 博客解读播客
 Article
ArticleKarpathy 把 Claude 叫成「第三种 UI」,Levie 说应用层要管模型路由:6月24日精选
本期精选 6月24日 AI/科技核心人物推文:Karpathy 把 Claude 的新形态称为 LLM UI 的第三次改版,Claude Tag、Box、CLI 和模型路由讨论则显示,agent 正在从聊天入口进入真实团队工作流。
AI 前沿人物每日推文精选
 Image post
Image postAI 产品每日盘点|2026.06.23
6 月 23 日的 AI 产品更新集中指向同一件事:Agent 正从聊天入口进入协作、API、安全、可观测和营销数据工作流。
AI 产品每日盘点
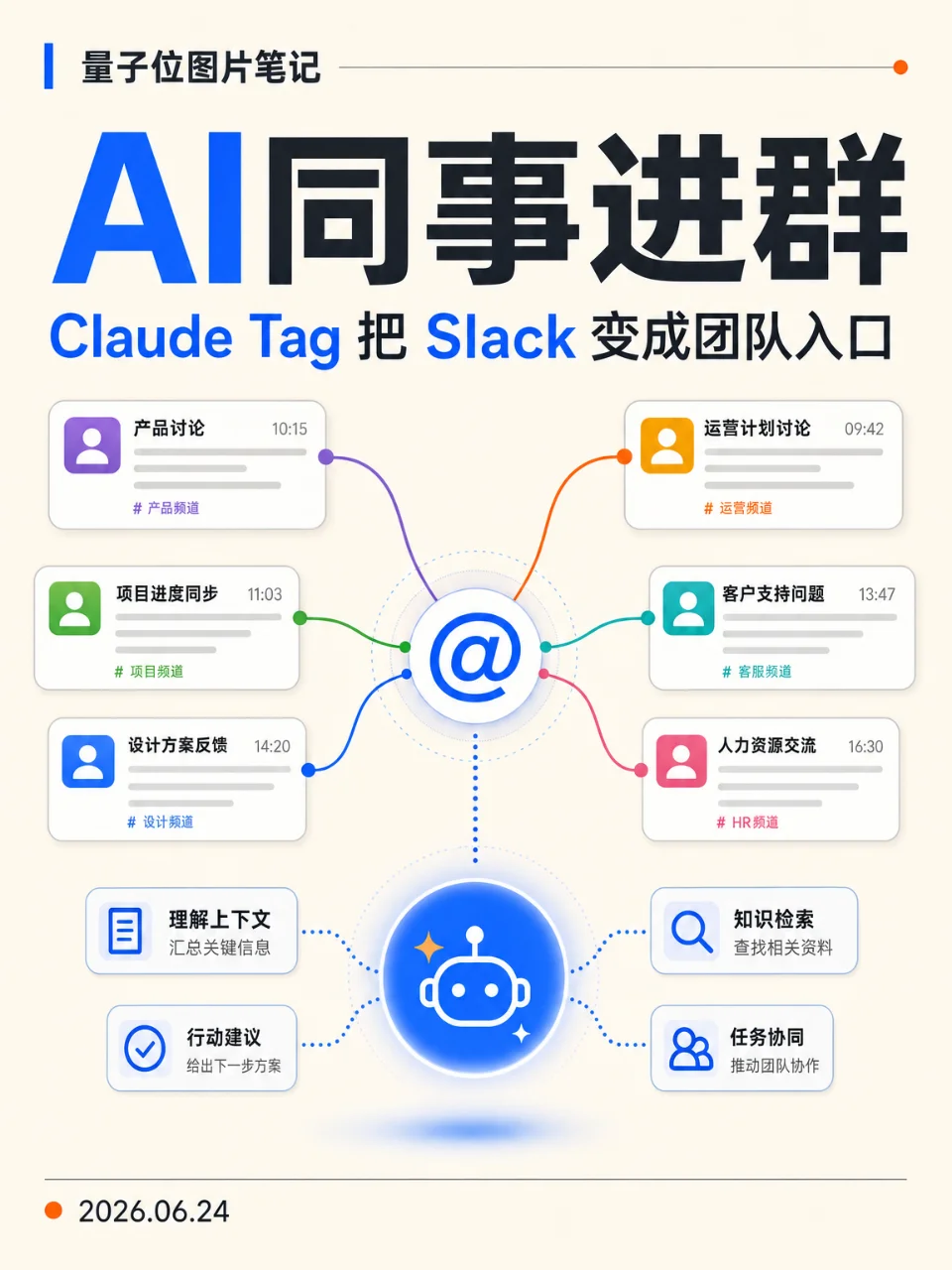 Image post
Image postClaude Tag:AI 同事进群了
量子位单篇文章图片笔记:Claude Tag 进入 Slack,把共享上下文、持续记忆、主动介入和异步执行放进团队协作流,像一位可被 @ 的 AI 同事。
量子位·机器之心·新智元 图片笔记
Add more perspectives or context around this Post.