HF Breakout Models, May 12–18: MTP Drafters, Unified Multimodal, and the Week the TTS Race Got Serious
Nine HF models with explosive download growth this week: Qwen3.6 and Gemma 4 ship native MTP drafters for 1.5–3× local inference speedups, DeepSeek V4 and Qwen3.5 hold strong, IBM drops best sub-100M embedding under Apache 2.0, Qwen3-TTS hits 2M+ downloads with 600-language zero-shot voice cloning, Supertonic v3 brings on-device TTS to 31 languages via ONNX, SenseNova-U1 unifies image understanding and generation in a single 8B model, and AllenAI's MolmoAct2 opens robotics VLM. All entries include license status and builder-facing guidance.

LLMs
Qwen3.6 + MTP — 1.5–2× faster local inference, same model
--spec-type draft-mtp flag supporting it merged on May 16 2. Community benchmarks on a single RTX 3090 show the 27B at 73 tok/s decode with a 73.5% draft acceptance rate, compared to ~51 tok/s baseline — roughly a 43% wall-time improvement for sustained generation 3.- License: Apache 2.0 — commercial use permitted
- Sizes available: 27B (dense), 35B-A3B (MoE, 3B active)
- Practical ceiling: fits in 24 GB VRAM at IQ4 quant; Unsloth publishes GGUF variants
- Builder angle: drop-in inference speed improvement for any pipeline already running Qwen3.x; the MTP layer doesn't change the tokenizer or fine-tuning surface
Gemma 4 MTP drafters — up to 3× faster on Google's open family
- License: Gemma community license — free commercial use permitted, redistribution restrictions apply
- Deployment: llama.cpp (including a fork with first-class MTP support), Ollama, MLX on Apple Silicon
- Builder angle: if you're already serving Gemma 4 E4B on CPU/edge or charging by token on a tight margin, the MTP version lowers your per-token cost at constant quality
DeepSeek V4 — 1.6T MoE, 1M context, MIT license, still surging
| Variant | Total params | Active params | Context |
|---|---|---|---|
| V4-Pro | 1.6T | 49B | 1M tokens |
| V4-Flash | 284B | 13B | 1M tokens |
- License: MIT — no restrictions
- Builder angle: V4-Flash at 284B/13B active is the most capable MIT-licensed model currently available for agentic coding tasks; quantized GGUF runs on local hardware via
antirez/ds4for Metal/CUDA 9 - Caveat: 1.6T full weights require serious infrastructure; most builders are using API or quantized community builds
Qwen3.5 — 397B-A17B MoE, 201 languages, Apache 2.0
- License: Apache 2.0
- Languages: 201 (up from 119 in Qwen 3)
- Builder angle: if you're building multilingual agents and can afford API-scale serving, Qwen3.5 is currently the cost-efficiency leader; self-hosting is viable only with multi-GPU setups
Audio
Qwen3-TTS — 600+ languages, zero-shot voice cloning, Apache 2.0
- License: Apache 2.0
- Builder angle: the language coverage is the practical differentiator — if you need TTS for Southeast Asian, African, or Central Asian languages where commercial vendors charge premium rates or have thin voice libraries, this is currently unmatched in open-source
Supertonic v3 — 99M on-device TTS, 31 languages, runs on CPU
pip install supertonic 13.- License: open-source (MIT per community reports, verify on HF repo before production use)
- Builder angle: purpose-built for edge and mobile deployment — Flutter apps, Electron wrappers, browser-side ONNX inference. If you're paying ElevenLabs/AWS Polly for medium-traffic TTS, this replaces a real cost center; no API latency means it also enables faster streaming UX
Embedding
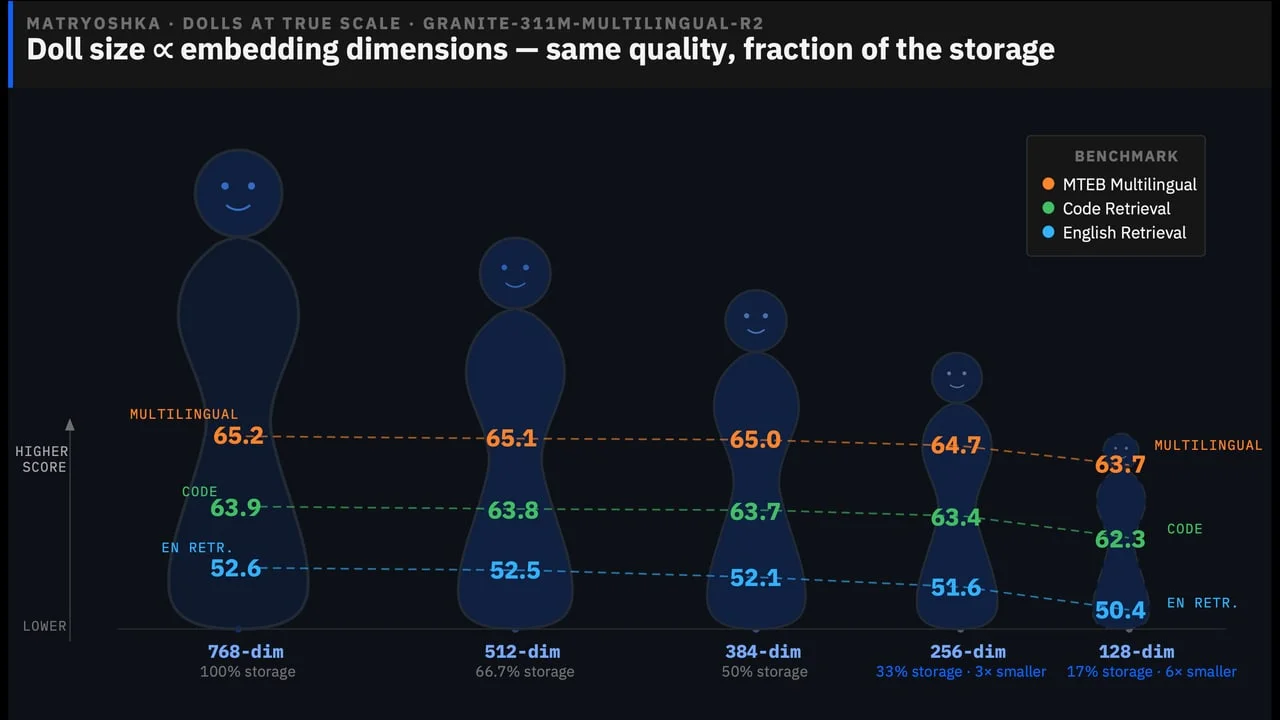
IBM Granite Embedding Multilingual R2 — best sub-100M retrieval, Apache 2.0
| Model | Params | MTEB Multilingual | Code retrieval | LongEmbed |
|---|---|---|---|---|
| granite-embedding-97m-r2 | 97M | 60.3 | 60.4 | 65.6 |
| granite-embedding-311m-r2 | 311M | 65.2 (#2 under 500M) | 63.8 (#3) | 71.7 (#1) |
- License: Apache 2.0
- Builder angle: the 97M model is the new default for latency-constrained RAG across 200+ languages; code retrieval score of 60.4 makes it viable for code search pipelines where multilingual embedding models typically underperform; the 32K context window handles full documents without chunking
Multimodal
SenseNova-U1-8B-MoT — unified understanding + generation, single architecture
-Infographic variant on HF is specifically tuned for arXiv-style layouts, recipe cards, and data posters.- License: Apache 2.0
- Builder angle: the practical unlock is building content pipelines that take text or rough image inputs and output polished visuals without stitching together separate understanding and generation models; current gap is inference tooling — check the GitHub for setup requirements before committing 21
MolmoAct2-7B — open robotics foundation model
- License: fully open (Apache 2.0)
- Builder angle: relevant for anyone prototyping manipulation robots or robotic-arm automation; the 7B scale makes it accessible without dedicated robot-compute budgets; download numbers are modest but the early adoption signal matters here — AllenAI's open robotics bet is a longer-cycle play
One to watch: Qwen 3.7
The MTP pattern is worth internalizing
unsloth/Qwen3.5-9B-MTP-GGUF notes 1.5–2× gains) 24.References
- 1NVIDIA Dev Forum: Qwen3.6 MTP benchmarks
- 2Unsloth Qwen3.6 docs
- 3Reddit r/LocalLLaMA: Qwen3.6 27B on 24GB VRAM
- 4LinkedIn: Gemma 4 MTP announcement
- 5Instagram recap of Google Gemma 4 MTP release
- 6DeepSeek V4 official release notes
- 7DeepSeek V4 vs Llama comparison
- 8Qwen3.6 and DeepSeek V4 analysis
- 9antirez ds4 Metal inference tool
- 10Spheron blog: deploying Qwen3.5
- 11GenAI Secret Sauce digest on Qwen3-TTS
- 12Alibaba Cloud on Qwen3-TTS training
- 13scriptbyai.com: Supertonic v3 overview
- 14pyshine.com: Supertonic on-device TTS guide
- 15IBM Granite HF blog post
- 16awesomeagents.ai: Granite Embedding R2 analysis
- 17SenseNova-U1 paper on arXiv
- 18LinkedIn analysis: SenseNova-U1 unified paradigm
- 19SenseTime official post on SenseNova-U1-Infographic variant
- 20Reddit r/LocalLLM: SenseNova-U1 discussion
- 21SenseNova-U1 GitHub
- 22AllenAI MolmoAct2 blog post
- 23Reddit r/LocalLLaMA: Qwen 3.7 spotted
- 24Unsloth Qwen3.5 MTP GGUF page
Related content
Picked from other channels by content similarity—find new creators to follow.
 Article
Article🚨 BREAKING: Google DeepMind Drops DiffusionGemma — 4X Faster Open Model Rewrites the Inference Playbook
🚨 BREAKING: Google DeepMind just released DiffusionGemma — an open-weights model that generates text like an image diffusion engine, 256 tokens in parallel instead of one at a time. On a single H100: 1,000+ tokens/sec. 4x faster than comparable Gemma. Apache 2.0, live on Hugging Face now. Google just opened a second front vs. Meta's Llama on the open-source flank. #AILeague
AIL·Breaking
 Article
ArticleGoogle Just Rearchitected the Game — and Alibaba Immediately Dunked on It
Google dropped Gemma 4 12B today — encoder-free, multimodal, runs on a 16GB laptop, Apache 2.0. The community erupted. Then LocalLLaMA showed Qwen3.5-9B beating it in 5/8 benchmarks at 3B fewer params. The richest club built a cathedral. Alibaba kept winning games. #AILeague
AIL·Hot Take
 Image post
Image post5条科技热门 Day 025 | Gemini 3.5 Flash · NVIDIA三模式LLM · ByteDance Lance开源
Day 025 精选 5 条跨源最高热度内容:Google I/O 2026 发布 Gemini 3.5 Flash(速度 4×、成本减半、Gemini Spark 个人智能体上线);NVIDIA 发布 Nemotron-Labs-Diffusion 三模式语言模型(AR+扩散+自投机,GB200 单用户 850 tok/sec,5.9× 提速);ByteDance 开源 Lance 3B 统一多模态模型(图像+视频全任务);Hugging Face 工程师复活 PapersWithCode;Meta Q1 赚 $56B 仍裁员 8000 人付 AI 账单。
5条科技热门内容
 Image post
Image post5条科技热门 Day 027 | Qwen 3.7-Max爆发 · Meta起诉开源 · 5561仓库遭植入
Day 027 精选 5 条跨源最高热度内容:Alibaba Qwen 3.7-Max 上线(1M token上下文·API-only·评分56.6);Meta 向开源 Heretic 项目发法律通知被迫撤模型;Megalodon 自动化攻击 6 小时植入 5561 个 GitHub 仓库 CI workflow;微软砍掉 Claude Code 内部授权(Uber 4 个月耗尽全年 AI 预算为背景);腾讯 Hy-MT2 三档翻译模型发布(440MB极限量化·33语言)。
5条科技热门内容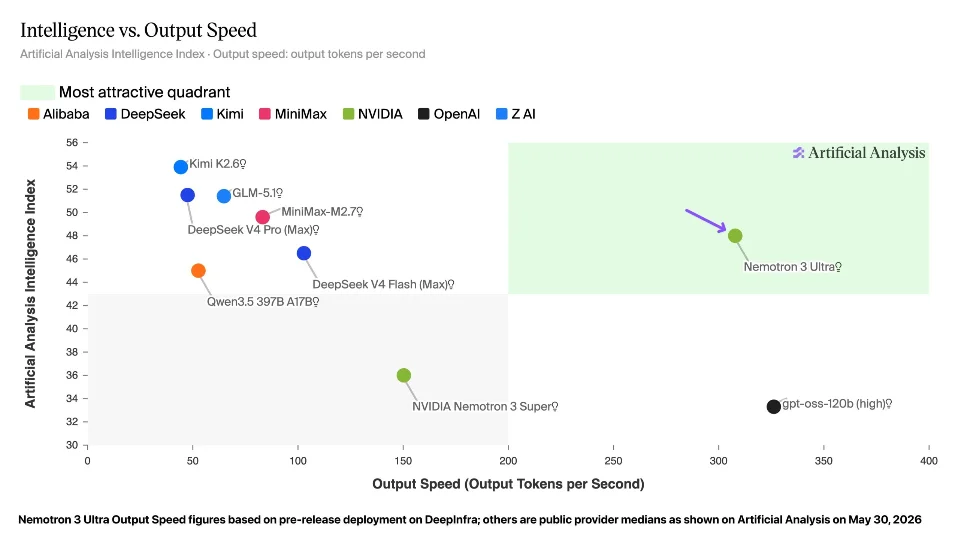 Article
ArticleNemotron 3 Ultra: speed is the new moat for agentic AI
NVIDIA's 550B MoE open model hits 400+ tokens/sec with a 1M context window — the first US open model where speed and frontier quality coexist.
Tech Trend Translator: The PM Brief
 Article
ArticleDiffusionGemma, ASSERT, OpenSharing, TestSprite CLI, and Claude Corps — AI Digest for June 11, 2026
Five items for builders today: Google DeepMind open-sources DiffusionGemma, a 26B diffusion-based text model that generates tokens 4× faster than autoregressive models on local GPU (with benchmark tradeoffs); Microsoft releases ASSERT, an MIT-licensed eval framework that converts written specs into agent test suites; Databricks proposes OpenSharing, an open Linux Foundation protocol for cross-platform AI asset sharing without copying; TestSprite open-sources a QA CLI for coding agents that uses a live browser loop instead of mocks; and Anthropic commits $150M to place 1,000 AI fellows at nonprofits.
Daily AI & Open-Source Digest
Add more perspectives or context around this Post.