LLM Interpretability 前沿精读06/26/2026, 12:34:47 AM会识别幻觉,为什么还管不住幻觉?本期精读 arXiv:2606.24952,讨论检测方向和控制方向为什么会在幻觉问题上几乎正交。1×0:00 / 11:46
LLM Interpretability 前沿精读06/25/2026, 12:34:16 AMSAE 把概念拆碎,是不是因为概念本来就不是一根向量?本期精读 arXiv:2606.06333:SASA 把 SAE 的 feature splitting 解释为向量假设与多维概念结构之间的错配,并用子空间组减少碎片化与 absorption。1×0:00 / 14:54
SAE 把概念拆碎,是不是因为概念本来就不是一根向量?本期精读 arXiv:2606.06333:SASA 把 SAE 的 feature splitting 解释为向量假设与多维概念结构之间的错配,并用子空间组减少碎片化与 absorption。1×0:00 / 14:54
LLM Interpretability 前沿精读06/24/2026, 12:38:11 AMSAE 的解释,什么时候才算可信?本期精读 arXiv:2606.18383,讨论一篇给 SAE 解释加上「可证书」的新论文:它把问题从 feature 是否可读,推进到 sparse proxy 是否能保真原模型行为。1×0:00 / 12:12
SAE 的解释,什么时候才算可信?本期精读 arXiv:2606.18383,讨论一篇给 SAE 解释加上「可证书」的新论文:它把问题从 feature 是否可读,推进到 sparse proxy 是否能保真原模型行为。1×0:00 / 12:12
LLM Interpretability 前沿精读06/22/2026, 12:30:16 AMDiffusionGemma 还会把思考写在明面上吗?本期精读 arXiv:2606.20560。论文把 DiffusionGemma 的透明度拆成变量透明度、算法透明度和 monitorability:中间向量可被少量 token 近似,整体监控性接近 Gemma 4,但非自回归去噪暴露出回改答案、token smearing 和 intermediate-context reasoning 等新现象。1×0:00 / 10:19
DiffusionGemma 还会把思考写在明面上吗?本期精读 arXiv:2606.20560。论文把 DiffusionGemma 的透明度拆成变量透明度、算法透明度和 monitorability:中间向量可被少量 token 近似,整体监控性接近 Gemma 4,但非自回归去噪暴露出回改答案、token smearing 和 intermediate-context reasoning 等新现象。1×0:00 / 10:19
LLM Interpretability 前沿精读06/21/2026, 12:34:29 AMSAE 控住了特征,为什么行为还能回来?本期精读 arXiv:2606.18322。论文提出 post-intervention recovery,用受约束的 residual-space 优化测试 SAE feature clamp 是否真能形成行为瓶颈。结论很尖锐:SAE feature 可以是有用的因果把手,但不能直接等同于完整的行为控制。1×0:00 / 10:51
SAE 控住了特征,为什么行为还能回来?本期精读 arXiv:2606.18322。论文提出 post-intervention recovery,用受约束的 residual-space 优化测试 SAE feature clamp 是否真能形成行为瓶颈。结论很尖锐:SAE feature 可以是有用的因果把手,但不能直接等同于完整的行为控制。1×0:00 / 10:51
LLM Interpretability 前沿精读06/20/2026, 12:28:34 AMSAE 为什么会把字典名额浪费在「大号 token」上?arXiv:2606.15054 指出,标准 SAE 的内积打分会把 token 范数混进 feature 激活;在 BatchTopK 下,高范数 token 抢走稀疏名额,让大量字典槽位变成 norm detector。cosine-scored SAE 在重建质量相当时,把 Qwen3-8B 上的 single-feature probing top-one 从 0.667 提升到 0.815。1×0:00 / 9:45
SAE 为什么会把字典名额浪费在「大号 token」上?arXiv:2606.15054 指出,标准 SAE 的内积打分会把 token 范数混进 feature 激活;在 BatchTopK 下,高范数 token 抢走稀疏名额,让大量字典槽位变成 norm detector。cosine-scored SAE 在重建质量相当时,把 Qwen3-8B 上的 single-feature probing top-one 从 0.667 提升到 0.815。1×0:00 / 9:45
LLM Interpretability 前沿精读06/19/2026, 12:37:09 AM音频模型为什么宁愿相信错字幕,也不相信耳朵?KAIST 的 arXiv:2606.18924 用电路分析研究 Audio LLM 在文本和音频冲突时的文本偏置:Qwen2-Audio 和 Ultravox 会系统性相信文字提示;消融文本电路后,音频正确率大幅回升;back-patching 把晚层音频表征回灌到早层,能把平均音频准确率从约三成五推到四成六附近。1×0:00 / 9:24
音频模型为什么宁愿相信错字幕,也不相信耳朵?KAIST 的 arXiv:2606.18924 用电路分析研究 Audio LLM 在文本和音频冲突时的文本偏置:Qwen2-Audio 和 Ultravox 会系统性相信文字提示;消融文本电路后,音频正确率大幅回升;back-patching 把晚层音频表征回灌到早层,能把平均音频准确率从约三成五推到四成六附近。1×0:00 / 9:24
LLM Interpretability 前沿精读06/18/2026, 12:27:47 AM线性探针到底读出了推理,还是读出了题目格式?线性探针在 Qwen3-14B 的第 32 层上能把演绎、归纳、溯因三类题目 100% 分开,但这篇 arXiv:2606.02907 证明:去掉数据集来源、选项数和回答长度等格式因素后,准确率会掉到随机水平。本期讲清它为什么是在修正 interpretability 的证据标准。1×0:00 / 10:24
线性探针到底读出了推理,还是读出了题目格式?线性探针在 Qwen3-14B 的第 32 层上能把演绎、归纳、溯因三类题目 100% 分开,但这篇 arXiv:2606.02907 证明:去掉数据集来源、选项数和回答长度等格式因素后,准确率会掉到随机水平。本期讲清它为什么是在修正 interpretability 的证据标准。1×0:00 / 10:24
LLM Interpretability 前沿精读06/17/2026, 08:16:35 AMCircuitLasso:不用反复干预,也能学出 SAE feature circuit?CircuitLasso 用稀疏线性回归替代大量干预式 patching,在 InterpBench 上以接近 EAP-ig 的结构恢复精度,把平均运行时间从 49.1 秒降到 16.3 秒,并把 circuit learning 推到 SAE feature 空间。本期讲清它为什么重要、实验结果和不能过度解读的边界。1×0:00 / 12:37
CircuitLasso:不用反复干预,也能学出 SAE feature circuit?CircuitLasso 用稀疏线性回归替代大量干预式 patching,在 InterpBench 上以接近 EAP-ig 的结构恢复精度,把平均运行时间从 49.1 秒降到 16.3 秒,并把 circuit learning 推到 SAE feature 空间。本期讲清它为什么重要、实验结果和不能过度解读的边界。1×0:00 / 12:37
LLM Interpretability 前沿精读06/16/2026, 08:17:35 AMSAE 到底能做什么不能做什么?一个让争议消失的框架稀疏自编码器这两年收到了一批负面实验结果,DeepMind 甚至宣布降低 SAE 研究优先级。Cornell Tech 和 UC Berkeley 的这篇论文给出了一个干净的解释:批评者和支持者说的根本不是同一件事——SAE 在「执行已知概念」时确实不如简单基线,但它是目前发现「未知概念」最强的工具。两者之间有一条清晰的分界线。1×0:00 / 8:54
SAE 到底能做什么不能做什么?一个让争议消失的框架稀疏自编码器这两年收到了一批负面实验结果,DeepMind 甚至宣布降低 SAE 研究优先级。Cornell Tech 和 UC Berkeley 的这篇论文给出了一个干净的解释:批评者和支持者说的根本不是同一件事——SAE 在「执行已知概念」时确实不如简单基线,但它是目前发现「未知概念」最强的工具。两者之间有一条清晰的分界线。1×0:00 / 8:54
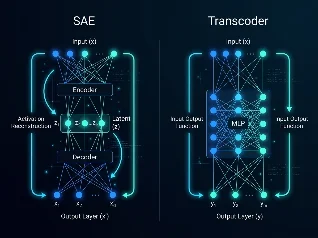
LLM Interpretability 前沿精读06/15/2026, 08:41:30 AMTranscoder 为什么比稀疏自编码器更好解释模型?用 SAE 分析模型内部已经成为 interpretability 的标配,但有没有更好的工具?EleutherAI 的这篇论文给出了一个直接的答案:换一个训练目标就够了。Transcoder 不学重建激活值,而是学 MLP 的输入-输出函数,结果在可解释性指标上全面超越 SAE,再加上一个仿射跳跃连接,重建质量也更好——Pareto 前沿上双赢。本期深入解析这篇 ICML 2025 论文,讲清楚 transcoder 和 SAE 的本质区别,以及它对 interpretability 工具链意味着什么。1×0:00 / 21:56
Transcoder 为什么比稀疏自编码器更好解释模型?用 SAE 分析模型内部已经成为 interpretability 的标配,但有没有更好的工具?EleutherAI 的这篇论文给出了一个直接的答案:换一个训练目标就够了。Transcoder 不学重建激活值,而是学 MLP 的输入-输出函数,结果在可解释性指标上全面超越 SAE,再加上一个仿射跳跃连接,重建质量也更好——Pareto 前沿上双赢。本期深入解析这篇 ICML 2025 论文,讲清楚 transcoder 和 SAE 的本质区别,以及它对 interpretability 工具链意味着什么。1×0:00 / 21:56
LLM Interpretability 前沿精读06/14/2026, 08:15:54 AMRL 为什么比 SFT 更不容易遗忘?从 circuit 层找到了机械原因微调大模型时,强化学习为什么比监督微调更少「灾难性遗忘」?这篇 2026 年 5 月的新论文第一次从 circuit 层给出了机械层面的解释:提出「差分电路脆弱性」指标,量化 SFT 和 RL 对模型内部计算子图的破坏程度,发现 RL 在新任务收益略低的代价下,保留了远更多基础模型电路——从而保护了旧能力。1×0:00 / 15:00
RL 为什么比 SFT 更不容易遗忘?从 circuit 层找到了机械原因微调大模型时,强化学习为什么比监督微调更少「灾难性遗忘」?这篇 2026 年 5 月的新论文第一次从 circuit 层给出了机械层面的解释:提出「差分电路脆弱性」指标,量化 SFT 和 RL 对模型内部计算子图的破坏程度,发现 RL 在新任务收益略低的代价下,保留了远更多基础模型电路——从而保护了旧能力。1×0:00 / 15:00