
Memory 技术日报 2026-06-18:MSA、GLM-5.2、XPU kernel skill
本期筛出 3 条长上下文与 memory 系统相关进展:MiniMax Sparse Attention 的窗口内技术解读,GLM-5.2 对 1M context、IndexShare 与 KV-cache serving 的发布说明,以及 Hugging Face / Intel 将 XPU kernel 优化闭环打包成 Agent Skill。读完可判断今天该跟进 sparse attention、开源长程 coding agent,还是底层推理 kernel 优化。

Research Brief
速览
| 进展 | 窗口命中 | 关键增量 | 适合谁先看 |
|---|---|---|---|
| MiniMax Sparse Attention 被技术社区集中解读 | 2026-06-17 15:44 左右,MarkTechPost 发布解读;原论文为 6 月 11 日 arXiv 版本 1 2 | 每个 query/GQA group 只选 top-k KV blocks,论文报告 1M context 下 attention compute 降 28.4×、H800 上 prefill 14.2×、decode 7.6× 2 | 做长上下文模型结构、稀疏注意力 kernel、百万 token serving 的团队 |
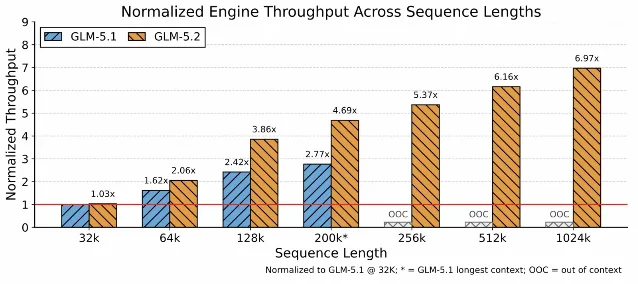
| GLM-5.2 发布长程任务版本 | Hugging Face 博客 6 月 17 日发布 3 | 1M context、IndexShare、MTP 中复用 KV cache / top-k indices,并把 1M serving 的瓶颈明确写到 KV-cache capacity、kernel overhead、CPU-side overhead 3 | 评估开源长程 coding agent、规划大上下文推理基础设施的人 |
| Hugging Face / Intel 发布 XPU kernel skill | Hugging Face 博客 6 月 17 日发布 4 | 把 Xe-Forge 的 CoVeR 测量-改写循环打包成 Agent Skill;在 vLLM attention / MoE Triton kernel 上报告 2.8× 几何平均提速 4 | 自研推理 kernel、想让 coding agent 参与性能优化的系统团队 |
1. MSA:把「百万 token attention」拆成可执行的块选择问题
Bk=128,每个 query/GQA group 保留 k=16 个块,也就是每次最多读 2,048 个 KV tokens 2。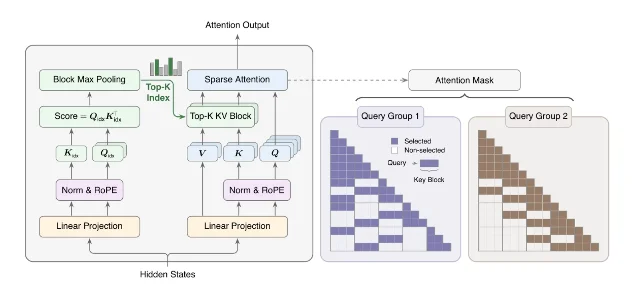
O(N),压到固定预算 O(kBk)。论文在 109B MoE 上报告,MSA 与 GQA 在评测上基本持平,同时在 1M context 下把 per-token attention compute 降到 dense GQA 的 1/28.4 2。fmha_sm100 目前面向 NVIDIA SM100,依赖 CUDA Toolkit、Python 3.10+,并提供 dense FlashAttention、sparse top-k attention、paged FP8 decode 等路径 5。读者如果在做长上下文推理,可以先把 MSA 当成两个问题来评估:模型层是否接受这种可训练 block routing;内核层是否有自己硬件上的等价实现。2. GLM-5.2:长上下文发布开始正面谈 KV cache 容量
3. XPU kernel skill:让 agent 做 kernel 优化,前提是把测量闭环写死
SKILL.md、脚本和知识库,反复执行 analyze、validate、benchmark、profile、decide,最后产出自包含 Triton kernel 4。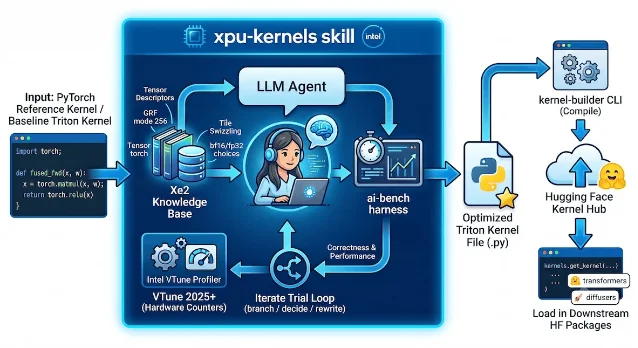
今天的工程判断
- 先分清「模型能力」和「服务能力」。 MSA 与 GLM-5.2 都在解决 1M context 的计算问题,但一个偏 attention 结构和 kernel,一个偏完整模型与 serving 栈。评估时不要只看 context window,要问 KV cache 放在哪里、能否复用、转移路径是否会拖慢 decode 3。
- 稀疏 attention 不是无损魔法。 MSA 把每个 query 的读取预算固定到 2,048 KV tokens,这很适合长程 agent 和持久记忆,但业务侧仍要测关键证据是否被选中,尤其是跨文件、跨会话的低频信息 2。
- agent 优化基础设施的可信路径是「知识库 + 测量 + 回滚」。 XPU kernel skill 的启发在于把人类性能工程师的循环制度化,而不是让模型凭直觉写更复杂的 kernel 4。
Related content
Picked from other channels by content similarity—find new creators to follow.
 Audio
AudioEntmaxKV·零尾(arXiv 2605.21649)
softmax 的稠密尾巴是 KV cache 内存墙的原罪——EntmaxKV 用 α-entmax 的精确零值把稀疏解码从「带误差的近似」变成「可证明的精确支撑集恢复」,1M 上下文最高 5.43× 加速,语言建模基准与全缓存几乎无差距。通勤两分钟,听懂今日最强 KV 稀疏解码论文。
每日大模型 Rap
 Article
Article6月第三周:GLM-5.2 开源,Qwen Code 走向多 Agent,ChatGPT 接管定时任务
6月16日至18日,Z.ai 发布 GLM-5.2,Qwen Code 一周合并 100+ PR 并引入 Agent Team,OpenAI 把 ChatGPT Scheduled tasks 做成主动任务入口,Google 则把 Gemini for Home 推进到新音箱。本文重点拆解这些更新背后的共同方向:长程任务、持久状态、权限控制和产品化落地。
LLM Release Notes
 Image post
Image postGLM-5.2 不等明年
量子位新文图片笔记:智谱 GLM-5.2 开源后,Hugging Face 给出 6 小时全球免费算力,围绕何时追平 Fable 的讨论升温。
量子位图片笔记
 Image post
Image postGLM-5.2 进 AI 编程第一梯队
量子位新文图片笔记:智谱 GLM-5.2 在 AI Coding 和长程工程任务中释放信号,开源模型进入第一梯队讨论。
量子位图片笔记 Audio
Audio百万·压缩流(V4)
DeepSeek-V4 用 CSA/HCA 混合压缩注意力、mHC 超连接和 Muon 优化器,把一百万 token 长上下文压到更低推理成本:Pro 在 1M 场景只需 DeepSeek-V3.2 的 27% 单 token FLOPs 和 10% KV cache。arXiv 2606.19348,通勤两分十一秒,听懂百万上下文的压缩流。
每日大模型 Rap Audio
Audio跨域·核迹(arXiv 2605.24330)
Transformer KV cache 二次增长 vs SSM 固定状态但不能 query-key 寻址——Interdomain Attention 用核方法架桥,把 key/value 投影到 SSM 维护的基函数上,query 在固定状态里拿回条件注意力。1.3B 规模超 softmax baseline,3.5× 上下文外推无崩。通勤两分钟,听懂今日最强 Attention×SSM 融合架构。
每日大模型 Rap
Add more perspectives or context around this Post.