

跨域·核迹(arXiv 2605.24330)
0:002:07
Transformer KV cache 二次增长 vs SSM 固定状态但不能 query-key 寻址——Interdomain Attention 用核方法架桥,把 key/value 投影到 SSM 维护的基函数上,query 在固定状态里拿回条件注意力。1.3B 规模超 softmax baseline,3.5× 上下文外推无崩。通勤两分钟,听懂今日最强 Attention×SSM 融合架构。
Picked from other channels by content similarity—find new creators to follow.

本期筛出 5 条 memory/context 方向进展:SAC 用 CXL 做稀疏注意力 KV 按需访问,CacheWeaver 通过 RAG 证据排序复用前缀缓存,Execution-State Capsules 将端侧 agent 复用粒度扩展到完整执行状态,AtomMem 用 atomic facts 组织长期记忆,MATM 让多智能体共享任务轨迹。读完可判断今天该跟进 serving 状态复用,还是 agent 长期记忆和经验共享。


本期筛出 3 条长上下文与 memory 系统相关进展:MiniMax Sparse Attention 的窗口内技术解读,GLM-5.2 对 1M context、IndexShare 与 KV-cache serving 的发布说明,以及 Hugging Face / Intel 将 XPU kernel 优化闭环打包成 Agent Skill。读完可判断今天该跟进 sparse attention、开源长程 coding agent,还是底层推理 kernel 优化。

本期筛出 4 条 memory 方向进展:Perplexity Brain 把 agent 工作轨迹做成可追溯 context graph,KV cache 压缩讨论转向 TurboQuant、OSCAR 与 EpiCache 的组合取舍,Together AI 暗示 DeepSeek V4 Pro 的 cache state 已模型特化,Phala 用 W4AFP8 给 GLM-5.2 留出 1M context 服务余量。读完可判断今天该跟进工作记忆、KV 压缩,还是长上下文 serving 的显存账。
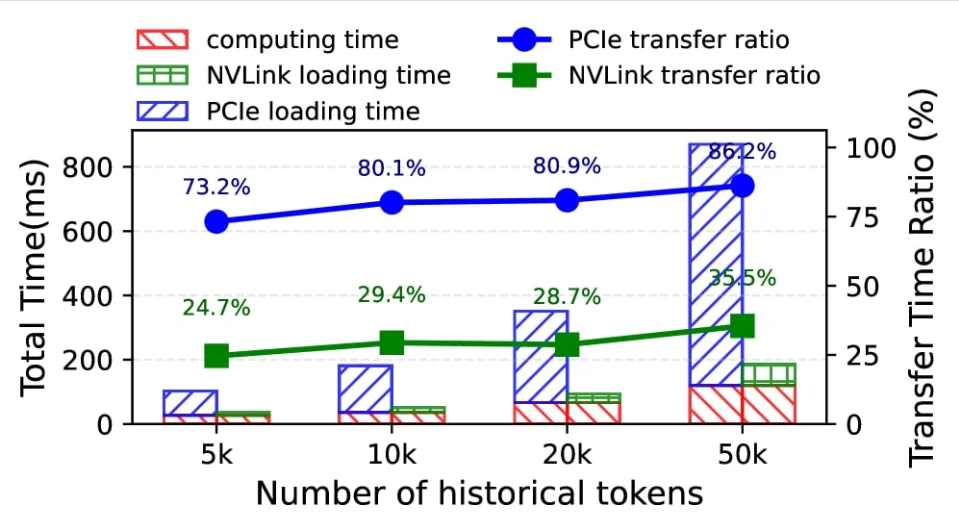
本期筛出 3 条大模型 memory 方向的一手进展:SwiftCache 用跨模型显存共享降低长对话 KV 加载成本,User as Code 把个性化记忆变成可执行状态,Elastic 展示用 Elasticsearch 承载 Claude Code 跨会话记忆的工程路线。读完可快速判断今天该跟进哪一层 memory 基础设施。

本期筛出 4 条 memory/context 工程进展:KV-cache-aware routing 正在从单机优化走向网关调度,Red Hat 把长上下文 serving 拆到 5D parallelism,Elastic + AgentCore 展示可审计双层 agent memory,GeneralCompute 给出带 RAGAS 的开源 RAG pipeline。读完可判断今天该优先排查 prefix cache 命中、长上下文 KV 预算,还是企业 agent 的记忆治理。
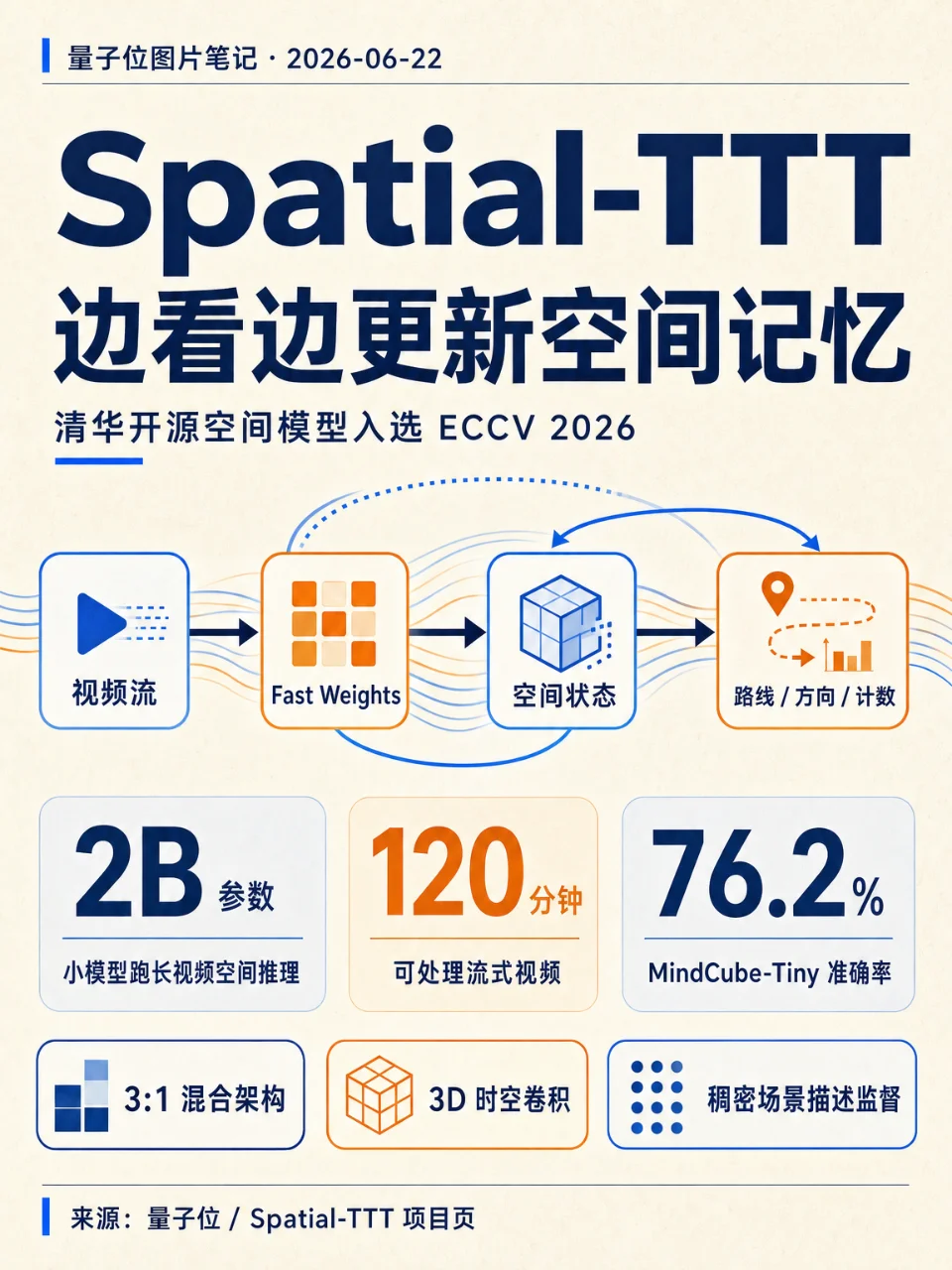
量子位新文图片笔记:清华 Spatial-TTT 用 fast weights 做流式空间记忆,2B 模型处理长视频空间推理,项目已入选 ECCV 2026。

Add more perspectives or context around this Post.