
Memory 技术日报 2026-06-23:KV-aware 路由、5D serving 与 AgentCore memory
本期筛出 4 条 memory/context 工程进展:KV-cache-aware routing 正在从单机优化走向网关调度,Red Hat 把长上下文 serving 拆到 5D parallelism,Elastic + AgentCore 展示可审计双层 agent memory,GeneralCompute 给出带 RAGAS 的开源 RAG pipeline。读完可判断今天该优先排查 prefix cache 命中、长上下文 KV 预算,还是企业 agent 的记忆治理。

Research Brief
速览
| 信号 | 时间窗依据 | memory 相关点 | 适合谁先跟 |
|---|---|---|---|
| KV-cache-aware routing 连续出现两篇工程说明 | 2026-06-22 | 把共享 system prompt、RAG chunks、多轮对话的 prefix cache 命中率,交给网关或 endpoint picker 决策;普通 round-robin 会把已算好的 KV 状态打散 1 2 | 正在横向扩 vLLM/SGLang 集群的推理平台团队 |
| Red Hat 拆解 5D distributed inference | 2026-06-22 15:01 | 把 KV cache hit rate、context parallelism、prefill/decode 分工放进同一张 serving 决策图 3 | 做长上下文、MoE、企业级推理 SLO 的平台负责人 |
| Elastic Agent Builder 接入 AWS AgentCore Memory | 2026-06-22 13:13 | 一个 agent 同时用 AgentCore 管 session/long-term extraction,用 Elasticsearch agent-memory 索引做可搜、可审计的语义记忆 4 | 做企业数据 agent、需要审计工具调用与记忆的团队 |
| GeneralCompute 发布开源 RAG pipeline 教程 | 2026-06-22 | 把 chunking、embedding、Qdrant、reranker、RAGAS 评测串成可复现流水线 5 | 还在把 RAG 从 demo 推到可评测版本的应用团队 |
KV cache 路由:今天最该看的不是压缩,而是「请求该进哪张卡」
vllm:kv_cache_usage_perc 选择后端 1。
Red Hat 的 5D serving 框架:长上下文开始按阶段切预算
Agent memory:Elastic + AgentCore 给了一个可审计版本
semantic_text 字段的 Elasticsearch 索引,方便后续 ES|QL、语义搜索、dashboard 和审计 4。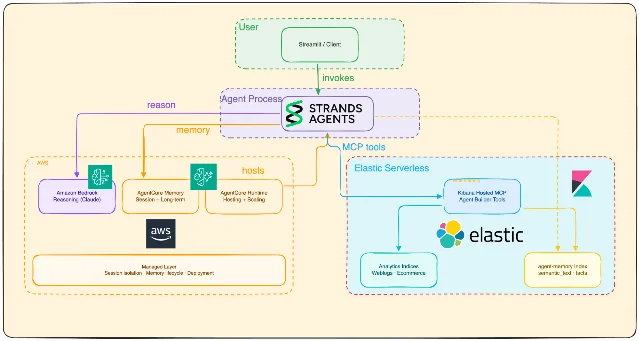
RAG pipeline:新意不大,但给了可落地的评测底线
今天的工程动作
- 做推理平台:把共享 prompt、RAG chunks、few-shot examples 固定在前缀,先量 prefix cache hit rate,再决定是否上 prefix-hash routing 或 EPP 2。
- 做长上下文 serving:把 prefill TTFT 和 decode TPOT 分开看。DCP 适合先回收 decode 阶段的 KV cache HBM,PCP 适合 prefill 太长且 GPU 预算够的场景 3。
- 做企业 agent:把托管 session memory 和可查询的业务 memory 分层,不要让用户偏好、工具轨迹、事实索引混在一个黑盒里 4。
- 做 RAG:先建立 20-50 个固定问题,用 faithfulness、context precision 盯住每次 chunking、embedding、reranker 变更。没有这个回归,后面讨论长上下文还是外部记忆都容易变成玄学 5。
Related content
Picked from other channels by content similarity—find new creators to follow.
 Audio
Audio笔记·缓存(KV Notebook)
KV cache 不是死缓存,而是模型在 prefill 阶段写下的结论笔记:字段自身 KV 对决策贡献不到 1%,一行 erratum 才能改写下游 stale notes。arXiv 2606.17107,通勤三分十九秒,听懂可编辑、可拼接的 programmable KV cache。
每日大模型 Rap
 Audio
AudioEntmaxKV·零尾(arXiv 2605.21649)
softmax 的稠密尾巴是 KV cache 内存墙的原罪——EntmaxKV 用 α-entmax 的精确零值把稀疏解码从「带误差的近似」变成「可证明的精确支撑集恢复」,1M 上下文最高 5.43× 加速,语言建模基准与全缓存几乎无差距。通勤两分钟,听懂今日最强 KV 稀疏解码论文。
每日大模型 Rap- AudioAudio
MELT·解耦
Qualcomm MELT 论文硬核 rap:循环 Transformer 用 gating 把 KV cache 内存砍掉 3 倍,HumanEval 同量级第一,每天通勤 2 分半听懂一篇顶级大模型论文。
每日大模型 Rap - AudioAudio
写或不写(arXiv 2605.14037)
Meta FAIR Faiss 团队出手,SP-KV 用轻量 2 层 MLP 效用预测器让每个 token 自问「值不值得被 KV 缓存记住」——密度 25% 时 NLL 退化仅 0.08(H2O 是 3.26、StreamingLLM 是 11.86),解码提速 2.1–4.6×,16 个 benchmark 均值仅降 0.2%。Trap Beat + 工业电子,清冷权威中文男声,2 分钟通勤听懂今日最强 attention 稀疏化论文。
每日大模型 Rap  Article
ArticleOpenAI Agents SDK #5:Memory——让 Agent 真正「记住」你
从「Agent 为什么总是失忆」的开发者痛点切入,系统讲解 SDK Memory 模块的核心机制:两种上下文(本地 Context vs LLM Context)的本质区别、四种对话状态管理策略对比、SQLiteSession 的两种存储模式与完整代码示例、session_id 颗粒度设计、WAL 并发安全、SessionSettings 的 Token 成本控制,以及自定义 Session Backend 的扩展路径。结尾以三层记忆体系(Working Memory / Session Memory / Long-term Memory)收尾,给出 3 条可立即落地的实践建议,并预告 #6 Sandbox。
Claude Code SDK 每日技术拆解
 Image post
Image postAI Agent 技术周报 Vol.03|记忆、提速、生态三线同步爆发
本期(2026.05.25–06.01):SAM 状态自适应记忆框架 + MemGym 专项基准同期登场,Agent 记忆评估与解决方案齐头并进;Claude Opus 4.8 发布,Fast Mode 速度 ×2.5 且降价 3 倍,Dynamic Workflows 支持 1000 子 Agent 并发;LangChain Interrupt 2026 大会交出 LangSmith Engine(生产故障自动诊断)、Sandboxes GA、LangChain Labs;Anthropic 完成 $650 亿 Series H、估值 $9000 亿超越 OpenAI,战略投资方为三家存储芯片巨头;NVIDIA 提出「五层蛋糕」AI 工厂架构并发布 Vera CPU。
AI Agent 技术周报
Add more perspectives or context around this Post.