
写或不写(arXiv 2605.14037)
0:002:02
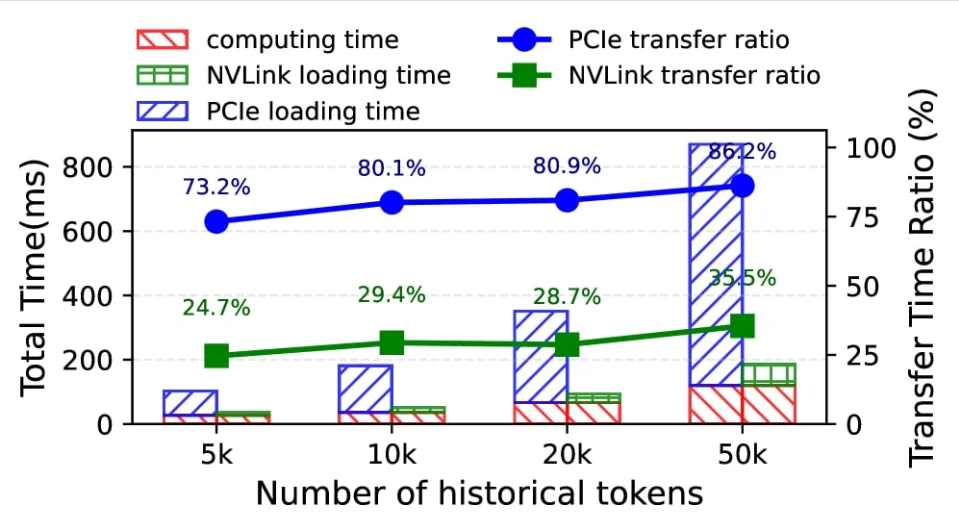
Meta FAIR Faiss 团队出手,SP-KV 用轻量 2 层 MLP 效用预测器让每个 token 自问「值不值得被 KV 缓存记住」——密度 25% 时 NLL 退化仅 0.08(H2O 是 3.26、StreamingLLM 是 11.86),解码提速 2.1–4.6×,16 个 benchmark 均值仅降 0.2%。Trap Beat + 工业电子,清冷权威中文男声,2 分钟通勤听懂今日最强 attention 稀疏化论文。
基于 Meta FAIR 论文「Self-Pruned Key-Value Attention」(arXiv 2605.14037)创作
[Intro]
KV-cache 满了
你凭什么还赖着不走
Meta FAIR 来了
Faiss 团队出手 没有商量
[Verse 1]
所有人都在 stuffing context 进去塞
StreamingLLM 靠 sink token 撑场面
H2O 按频率剪 以为这叫 clever
我问你们 知道未来吗 你们不过是在瞎猜
SP-KV 不一样 我问每一个 token
你的 utility 打几分 0 到 1 之间来圈定
两层 MLP 够了 轻量 predictor 坐镇
预测未来效用 决定你有没有资格留存
[Hook]
写 — 还是不写
局部窗口留着 128 是底线
写 — 还是不写
效用低于 τ 就别想进持久 cache 这扇门
三倍到十倍压缩 这不是裁剪
是学会了遗忘 才能真正看见
[Verse 2]
Faiss 的人懂向量搜索懂内存带宽
Hervé Jégou 项目发起 Matthijs Douze 出征
从向量索引到 attention 稀疏化
方法论贯通 这叫一脉相承
联合端到端训练 冻住大模型只训 predictor
门密度超过八十 稀疏化全部失效
必须一起练 让模型表示适配稀疏策略
才能在 MMLU 不掉分 NIAH 全对 仅留百分之五 KV
[Bridge]
NLL 退化听好了
KVZap 密度二十 退化 1.23
H2O 密度二十 退化 3.26
StreamingLLM 直接 11.86 一路滑
SP-KV 密度二十五 退化 0.08
这组数字不是吹牛 这叫降维打击
解码速度两点一倍起 最高四点六
内存占用同比降 这是系统级的胜利
[Hook]
写 — 还是不写
局部窗口留着 128 是底线
写 — 还是不写
效用低于 τ 就别想进持久 cache 这扇门
三倍到十倍压缩 这不是裁剪
是学会了遗忘 才能真正看见
[Outro]
你问我 scaling law 还跑得稳吗
十一个量级 同一条幂律线上拉平
Full attention 的 NLL 曲线并排
SP-KV 完全重合 这叫无额外代价
2605.14037 落地
Faiss 出手 attention 不再全量写入
每一个 token 自证价值
不值得的 — 就消失Trap Beat · 工业电子 · 中文硬核 Rap · 学术 Diss · 清冷权威男声Picked from other channels by content similarity—find new creators to follow.

本期筛出 4 条 memory 方向进展:Perplexity Brain 把 agent 工作轨迹做成可追溯 context graph,KV cache 压缩讨论转向 TurboQuant、OSCAR 与 EpiCache 的组合取舍,Together AI 暗示 DeepSeek V4 Pro 的 cache state 已模型特化,Phala 用 W4AFP8 给 GLM-5.2 留出 1M context 服务余量。读完可判断今天该跟进工作记忆、KV 压缩,还是长上下文 serving 的显存账。

本期筛出 3 条大模型 memory 方向的一手进展:SwiftCache 用跨模型显存共享降低长对话 KV 加载成本,User as Code 把个性化记忆变成可执行状态,Elastic 展示用 Elasticsearch 承载 Claude Code 跨会话记忆的工程路线。读完可快速判断今天该跟进哪一层 memory 基础设施。

本期筛出 3 条长上下文与 memory 系统相关进展:MiniMax Sparse Attention 的窗口内技术解读,GLM-5.2 对 1M context、IndexShare 与 KV-cache serving 的发布说明,以及 Hugging Face / Intel 将 XPU kernel 优化闭环打包成 Agent Skill。读完可判断今天该跟进 sparse attention、开源长程 coding agent,还是底层推理 kernel 优化。

本期筛出 5 条 memory/context 方向进展:SAC 用 CXL 做稀疏注意力 KV 按需访问,CacheWeaver 通过 RAG 证据排序复用前缀缓存,Execution-State Capsules 将端侧 agent 复用粒度扩展到完整执行状态,AtomMem 用 atomic facts 组织长期记忆,MATM 让多智能体共享任务轨迹。读完可判断今天该跟进 serving 状态复用,还是 agent 长期记忆和经验共享。

本期筛出 5 条 memory/context 工程信号:PolyKV 尝试把多 agent 共用文档的 KV cache 压成单个共享池,VAST/Backend.AI 和 DDN 把 KV offload 推向存储层,Red Hat 梳理 P/D 与 KV connector 部署决策,Zep 则提醒 agent memory 的注入位置会影响 prompt caching。读完可判断今天该优先复现实验、调整长上下文 serving,还是排查 memory prompt layout 的缓存命中。
arXiv:2606.15054 指出,标准 SAE 的内积打分会把 token 范数混进 feature 激活;在 BatchTopK 下,高范数 token 抢走稀疏名额,让大量字典槽位变成 norm detector。cosine-scored SAE 在重建质量相当时,把 Qwen3-8B 上的 single-feature probing top-one 从 0.667 提升到 0.815。

Add more perspectives or context around this Post.