
Memory 技术日报 2026-06-25:PolyKV、KV offload 与 Prompt Cache
本期筛出 5 条 memory/context 工程信号:PolyKV 尝试把多 agent 共用文档的 KV cache 压成单个共享池,VAST/Backend.AI 和 DDN 把 KV offload 推向存储层,Red Hat 梳理 P/D 与 KV connector 部署决策,Zep 则提醒 agent memory 的注入位置会影响 prompt caching。读完可判断今天该优先复现实验、调整长上下文 serving,还是排查 memory prompt layout 的缓存命中。

Research Brief
速览
| 进展 | 方向 | 时间窗依据 | 今天该怎么判断 |
|---|---|---|---|
| PolyKV 把多 agent 共享文档的 KV cache 做成单个压缩池,15 个 agent 的 4K context KV 内存从 19.8 GB 降到 0.45 GB;作者也明确说尚未测 TTFT/吞吐。1 | 多 agent KV 共享 | Medium 页面显示为本窗口内发布;GitHub 仓库可复现实验。2 | 值得复现实验,不宜直接当生产方案。优先看 3-bit/4-bit kernel 代价和每轮解压是否吃掉节省的显存收益。 |
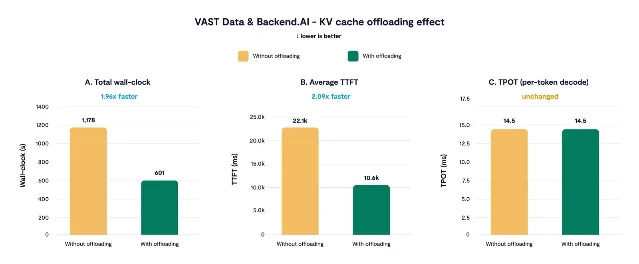
| VAST Data 与 Backend.AI 给出长上下文 agent coding 的 KV offload benchmark:8×H100、Mistral Medium 3.5 128B、140K-token 基础上下文下,总 wall-clock 从 1177.97s 降到 601.41s,平均 TTFT 从 22,104ms 降到 10,573ms。3 | KV 外溢与长期上下文 serving | 页面可见日期为 2026 年 6 月 24 日。 | 如果你的 workload 是「多个长前缀 agent session 轮转」,这比泛泛讨论 prefix cache 更接近生产容量问题。 |
| DDN 在 ISC 2026 相关发布里把 KV Cache acceleration 放进 EXAScaler/Infinia,称其与 NVIDIA Dynamo、vLLM 等集成,并给出「最高 55× faster KV cache loading」的供应商指标。4 | 存储厂商进入 KV cache 层 | 原文发布时间为北京时间 6 月 24 日 22:26。 | 这是供应链信号,不是独立 benchmark。适合放入 AI factory / 推理集群采购 watchlist。 |
| Red Hat 开发者文章把 P/D disaggregation、KVConnector、LMCache、MooncakeConnector、KV tiering/sharing/squeezing 放在同一套部署决策里,并称实验中 chat/RAG 形态 traffic 可降低 25%-40% 成本。5 | 分布式推理架构 | 页面可见日期为 2026 年 6 月 24 日。 | 更像工程 checklist:先量 prefill/decode GPU-seconds,再决定是否拆池、接哪种 KV 传输路径。 |
| Zep AI 提醒:如果每轮把检索出的 memory block 放进 system prompt,会破坏 prompt caching,使整段对话每轮重新付费;其建议是改一个 message placement。6 | agent memory 读路径 | 原帖发布时间为北京时间 6 月 25 日 07:04。 | 对 agent memory 产品很实用:记忆召回的位置会影响缓存命中率,不只是召回质量问题。 |
PolyKV:多 agent 共享同一份文档时,KV cache 可以从 N 份变 1 份
SharedKVPool,再让多个 PooledAgent 在生成时从同一个压缩池恢复 KV。仓库 README 也把这个目标写成「O(1) memory complexity in agent count」。2KV offload:长上下文 agent coding 的瓶颈正在从 HBM 挪到缓存路径
存储厂商开始把 KV cache 当作 AI data plane
Red Hat 的 checklist:先量 prefill/decode,再决定是否拆池
NixlConnector 更适合单集群 RDMA/NVLink;LMCacheConnector 适合跨实例 cache sharing 与 HBM/DRAM/NVMe tiering;MooncakeConnector 面向独立 KV-cache cluster。5Agent memory 的小坑:召回到 system prompt 可能打掉 prompt cache
今天的工程结论
References
- 1PolyKV: We Gave 15 AI Agents One Shared Memory and It Actually Worked
- 2GitHub - ishan1410/PolyKV
- 3Agent coding at long context: What KV cache offloading on VAST Data & Backend.AI buys you
- 4DDN launches faster array HW and KV Cache SW for AI
- 5Optimizing distributed AI inference: Advanced deployment patterns
- 6Zep AI on X: agent memory placement and prompt caching
Related content
Picked from other channels by content similarity—find new creators to follow.
 Audio
Audio笔记·缓存(KV Notebook)
KV cache 不是死缓存,而是模型在 prefill 阶段写下的结论笔记:字段自身 KV 对决策贡献不到 1%,一行 erratum 才能改写下游 stale notes。arXiv 2606.17107,通勤三分十九秒,听懂可编辑、可拼接的 programmable KV cache。
每日大模型 Rap
 Audio
AudioEntmaxKV·零尾(arXiv 2605.21649)
softmax 的稠密尾巴是 KV cache 内存墙的原罪——EntmaxKV 用 α-entmax 的精确零值把稀疏解码从「带误差的近似」变成「可证明的精确支撑集恢复」,1M 上下文最高 5.43× 加速,语言建模基准与全缓存几乎无差距。通勤两分钟,听懂今日最强 KV 稀疏解码论文。
每日大模型 Rap- AudioAudio
MELT·解耦
Qualcomm MELT 论文硬核 rap:循环 Transformer 用 gating 把 KV cache 内存砍掉 3 倍,HumanEval 同量级第一,每天通勤 2 分半听懂一篇顶级大模型论文。
每日大模型 Rap  Audio
Audio量化·崩塌(KV Cache Alignment Collapse)
KV cache 量化节省内存,但低比特量化可以在 perplexity 几乎不变的情况下静默摧毁安全对齐——Mistral-7B 仅 1.03× perplexity 代价就损失 15.2% 拒绝率,标准 benchmark 全程无感知。安全特征藏在比全空间脆弱一千倍的低维子空间,PCR 诊断三种失效模式,35 GPU 分钟可恢复 97% 对齐。通勤两分钟,听懂今日最犀利「量化省钱 谁来买单对齐」安全告警。
每日大模型 Rap- AudioAudio
写或不写(arXiv 2605.14037)
Meta FAIR Faiss 团队出手,SP-KV 用轻量 2 层 MLP 效用预测器让每个 token 自问「值不值得被 KV 缓存记住」——密度 25% 时 NLL 退化仅 0.08(H2O 是 3.26、StreamingLLM 是 11.86),解码提速 2.1–4.6×,16 个 benchmark 均值仅降 0.2%。Trap Beat + 工业电子,清冷权威中文男声,2 分钟通勤听懂今日最强 attention 稀疏化论文。
每日大模型 Rap  Audio
Audio百万·压缩流(V4)
DeepSeek-V4 用 CSA/HCA 混合压缩注意力、mHC 超连接和 Muon 优化器,把一百万 token 长上下文压到更低推理成本:Pro 在 1M 场景只需 DeepSeek-V3.2 的 27% 单 token FLOPs 和 10% KV cache。arXiv 2606.19348,通勤两分十一秒,听懂百万上下文的压缩流。
每日大模型 Rap
Add more perspectives or context around this Post.